Enhancing Data Quality with Label Studio Automated Workflows

Label Studio Team
As companies and organizations seek to leverage emerging AI technologies to drive value and efficiency, the quest for high-quality datasets is a key driver for model success. We recently held a webinar where we delved into the world of data quality utilizing Label Studio Enterprise’s automated workflows to ensure the creation of accurate, complete, and reliable datasets. This post will take you through the intricacies of data quality, the strategies employed to build top-tier datasets, and how to use Label Studio Enterprise to engineer your AI/ML success.
Data quality serves as the bedrock upon which successful machine learning models are built. But what do we mean when we talk about data quality? While there are many possible definitions, it can be succinctly summed up by the following: a high-quality dataset is accurate, complete, and reliable. Now we’ll go into more detail about each of these attributes.
Accurate labeling is the cornerstone of a high-quality dataset. It involves defining the ideal outcome of the model's desired output, ensuring that the annotations precisely align with the objectives of the machine learning task. This is generally achieved by having one or more human subject matter experts (SMEs) manually review and label the initial dataset. Having a group of experts agree on a common definition and categorization for each item represents the ideal outcome for the model once it’s trained on the data. Having this thoroughly-labeled data sets the stage for robust model training and predictive capabilities.
A complete dataset encompasses the full spectrum of scenarios and variations that the model is expected to encounter. It goes beyond accurate labeling to include edge cases, diverse classes, and comprehensive coverage of the data space. While it is nearly impossible for a dataset to contain every possible edge case that a model may encounter in production, the more diversity and depth a model is trained or fine-tuned on, the better the chances that the model will respond with accurate outcomes and predictions.
Reliability in datasets means having confidence in the model's predictions and their consistent performance across different iterations. A reliable dataset is one that produces predictable outcomes in repeated situations, where the model's behavior is stable and trustworthy. Establishing reliability in datasets is crucial for deploying machine learning solutions with confidence.
The trade-off between speed and quality in dataset creation is a common challenge faced by ML practitioners. Getting multiple annotations on each item, labeling a large number of items to ensure coverage across a number of edge cases, and having a strict review can ensure a highly accurate dataset, but is also very costly, particularly when the opportunity cost of having SMEs spend time labeling is figured into it. At the same time, when labeling is cursory
Label Studio offers a flexible framework that allows users to balance throughput and accuracy based on their specific needs. Whether optimizing for speed or depth, the platform provides tools to streamline the annotation process while maintaining data quality standards.
The workflow in Label Studio Enterprise is designed to facilitate the creation of accurate, complete, and reliable datasets. From annotating datasets to automated reviewer workflows and model performance evaluation tools, the platform offers a comprehensive suite of features to ensure data quality at every stage of the annotation process.

The quality workflow in Label Studio Enterprise begins with the actual annotation process. Label Studio features a highly-customizable labeling interface that allows you to provide custom labeling instructions to annotators and set up the UI to make labeling tasks intuitive and specifically-tailored to your use case. In addition, Label Studio's Machine Learning Backend supports integration of various models, facilitating pre-annotation and active learning. This allows labelers to adjust existing labels, significantly speeding up the process while maintaining accuracy. Ultimately, using these models enhances data quality by automating parts of the annotation workflow, increasing labeling accuracy, and speeding up dataset creation.
Once labeling commences, the next part of our quality workflow is the reviewer step. When you’re dealing with so many annotations and annotators, it’s important to have the ability to be prescriptive around the quality of the training data set that's going to feed your downstream model, whether it's for traditional classical machine learning or for gen AI evaluation. Label Studio Enterprise supports different roles such as manager, admin, and owner to oversee this process. These roles provide access to a data manager view that provides insights at the project level. In the data manager view, each row represents a task (which represents a piece of data that needs to be labeled; it could be an image, text, video, audio, or any of the other supported data types) And each column tells us something about that task, such as who did the annotation, has it been reviewed by a human SME, etc.
Label Studio also gives you the ability to import “ground truth” data that has already been annotated, agreed upon, and determined to be accurate and ideal for the project. This ground truth data allows the reviewer to leverage that ground truth data for comparison when evaluating the need for additional annotation or more annotator training. However, in the event that you don’t have ground truth data added to the project, you still have access to the inter-annotator agreement (IAA) score.
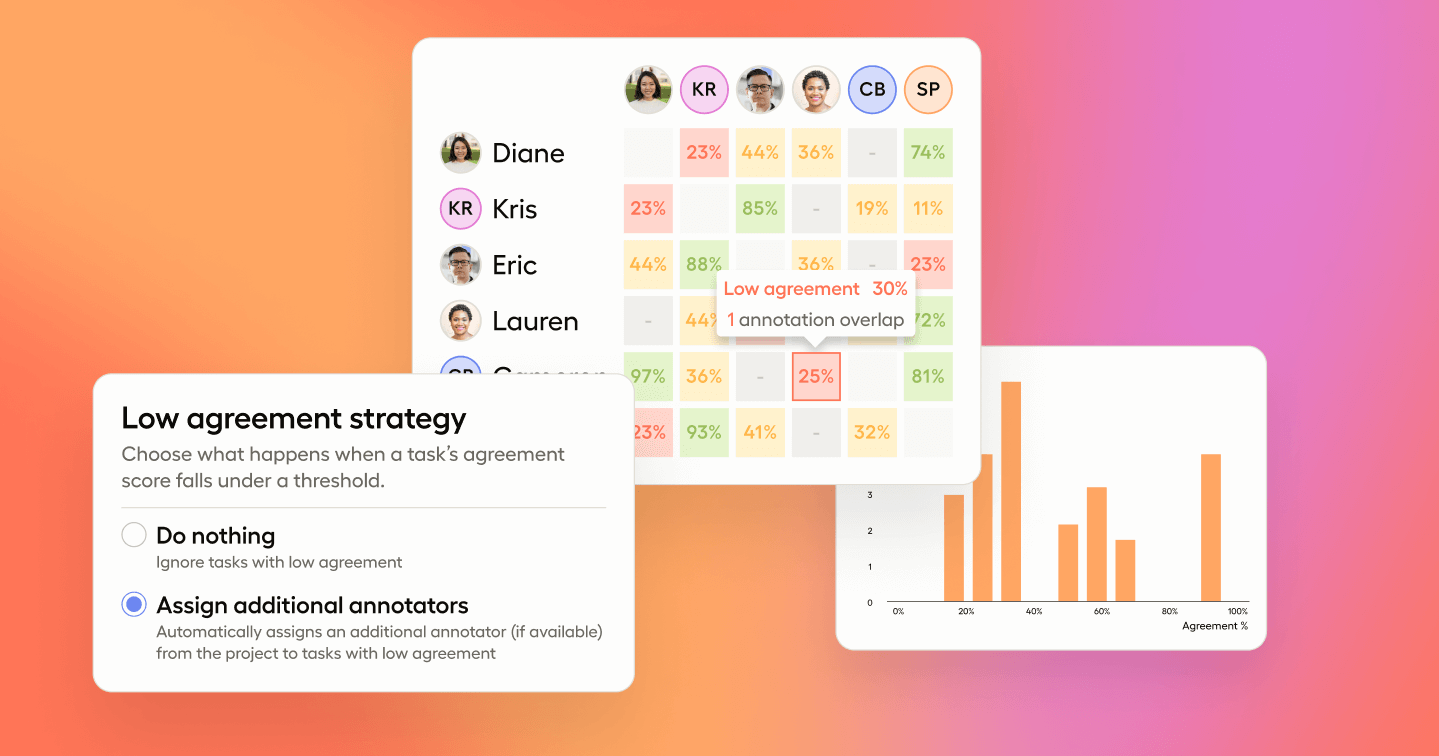
An important metric in Label Studio Enterprise is the inter-annotator agreement score (IAA), which measures how consistently different annotators understand and execute tasks. A low IAA score might indicate unclear instructions or fundamental issues with the tasks themselves. Managers can filter and order data in this "smart Excel sheet"-style interface to focus on tasks needing attention, using it to quickly identify and resolve discrepancies.
With all that said, here’s how the reviewer workflow looks in practice:
Let’s say that there are three annotators. A user with reviewer permissions can go into the data manager and quickly identify an item with a low agreement score, After clicking through to see what's causing the low agreement score, let’s say that it seems that one annotator is interpreting the label instructions differently and consequently the label is very different than the other annotations. The reviewer, as the SME, can quickly identify where the instructions are being interpreted incorrectly, at which point they can either reject the annotation, update the annotation themselves, or train the annotator further on the labeling instructions and have them adjust the annotation. And all of this can be done using keyboard shortcuts.
Label Studio also supports the automation of task assignments and reassignments. This allows users to configure and automate the balance between diversity and efficiency in task assignments. Early in a model's development, you can weight the task assignment mix towards more variety to ensure a robust dataset. As the model progresses, the focus may shift towards efficiency, having fewer annotators label each item in favor of completing more independent items. Regardless, there are settings in Label Studio that allow you to define the minimum number of annotations per task and the desired agreement percentage. This lets you facilitate strategic workflow adjustments based on project needs while drastically reducing management overhead.
While the previous example showcases how Label Studio makes manual task review and assignment/reassignment much easier and faster, we’ve actually built some newer features into this part of the quality workflow to make this step completely automated. After all, we know when a human looks at something, it is automatically more expensive, particularly if that human is a subject matter expert. So ideally you’re focusing human time almost completely on labeling or re-labeling tricky items rather than doing task management.
Task assignment automation is used in a couple of ways in Label Studio. First, you can configure initial task assignments to your team of annotators. We give you the ability to configure things like the minimum number of annotations for a given task, and what percentage of those tasks should have that minimum. Going back to our earlier discussion around quality vs. speed, these limits allow you to determine how to deploy annotator time - more annotations for greater accuracy, or fewer annotations for higher throughput. For example, if you're early on in your development of your ML model, maybe you need more variety to create a reliable and accurate and a complete data set. But as the model gets into production, you can narrow down the variety to more throughput - more sanity checks - making sure that the model predictions are exactly what they should be.
The other way that automated task assignment can be configured in Label Studio is to ensure that when there are items that need to be reviewed and re-labeled, those are automatically assigned. For example, say each task requires four annotations. You can define what agreement looks like - whether it's one of our out-of-the-box definitions or a custom definition - and anytime a task falls underneath the set definition, you can add additional annotators to try to bump the score over the threshold.
While initially we created some of Label Studio’s analytic features to help you compare performance between individual annotators, we’ve seen an emerging use case for model evaluation where these review features can be used to measure consensus across different model versions. Then these evaluations can be used to optimize deployment times and maximize competitive advantage. Leveraging versioning and consensus data helps identify whether a model is improving or deteriorating over time, which is crucial for strategic decision-making in model development.
One of the key metrics that Label Studio is capturing is what we call an IAA (Inter-Annotator Agreement) score. This score tells us how closely annotations across different labelers are matching up on a given task. This helps surface problematic instructions or tasks that aren’t resonating with annotators and are causing disagreements. With IAA scoring, reviewers can segment and filter the data based on this qualitative metric. So for example, you could look at the potentially thousands of tasks across a given project and narrow it down to five tasks where the IAA score is below a certain threshold.
In the end, the foundation of every successful machine learning model lies in the quality of its training data. With Label Studio's advanced capabilities and streamlined quality workflow, users have the tools they need to accurately, completely, and reliably generate datasets to power cutting-edge AI solutions. If you have any questions about how integrating these workflows into your AI project might work, schedule some time to talk with us!

A practical framework for turning AI metrics into clearer decisions about what to fix, ship, and scale.


A practical workflow for onboarding and evaluating annotators with clear instructions, calibration, quality gates, reviewer feedback, and dashboards that keep labeling consistent as volume grows.


A practical workflow for evaluating RAG and agent systems consistently through prompt, model, and workflow changes.
