RAG: Fundamentals, Challenges, and Advanced Techniques

Jimmy Whitaker
Data Scientist in Residence at HumanSignal
Data Scientist in Residence at HumanSignal
Retrieval-Augmented Generation (RAG) has become a go-to method for improving Large Language Models (LLMs). RAG helps mitigate issues like outdated information, high performance costs, and hallucinations, making it ideal for many real world applications.
At its core, RAG enhances an LLM by connecting it with external, domain-specific data sources to improve accuracy and relevance. RAG has gained traction as a more flexible and cost-effective alternative to fine-tuning—continued training on an existing model with specialized data—because it avoids complexities like model management, hyper-parameter optimization and significant resource usage (GPUs). Over the past year, a Menlo survey reported a 51% adoption rate of RAG among enterprise AI applications, however many organizations still struggle to implement it effectively.
The main struggle with RAG architectures is that it is highly flexible. Implementing it effectively for a particular use case requires careful data management, retrieval strategies, and continuous optimization. In this blog, is to lay out the building blocks of the RAG architecture. We’ll break down the fundamentals of RAG, explore recent advancements, and discuss how to improve a RAG system over time, while leaving exact areas of improvement that require human feedback for future posts.
Why do we need RAG in the first place? LLMs have well-known limitations: they can hallucinate, lack recent knowledge, and struggle with long context windows. While larger context windows are improving, they come with increased computational costs and often degrade accuracy. RAG helps address these issues by retrieving relevant information dynamically instead of relying solely on the LLM’s pre-trained knowledge.
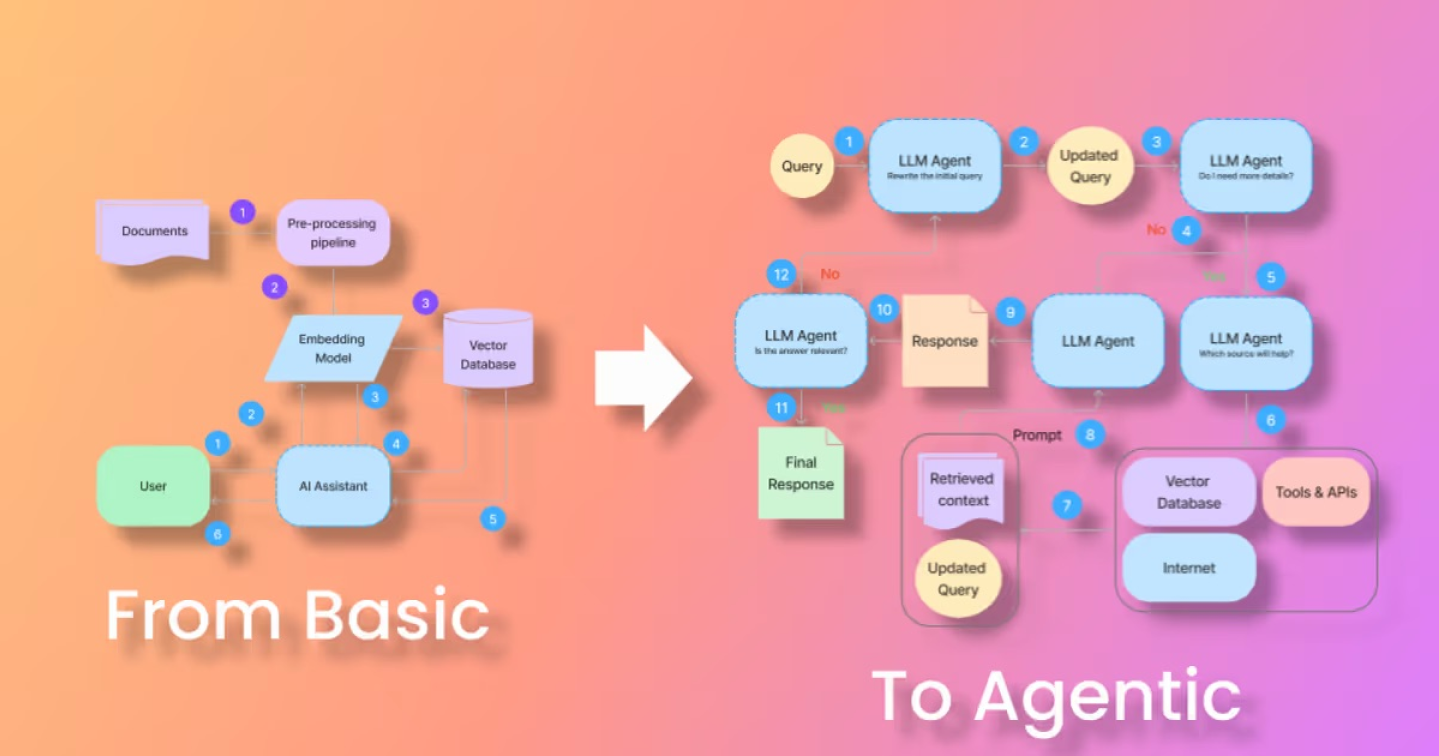
A RAG system retrieves relevant data to provide accurate responses—especially for topics an LLM wasn’t originally trained on. The system relies on a structured knowledge base that stores documentation, articles, manuals, and other domain-specific information that may be useful for answering specific questions correctly (Figure 1).
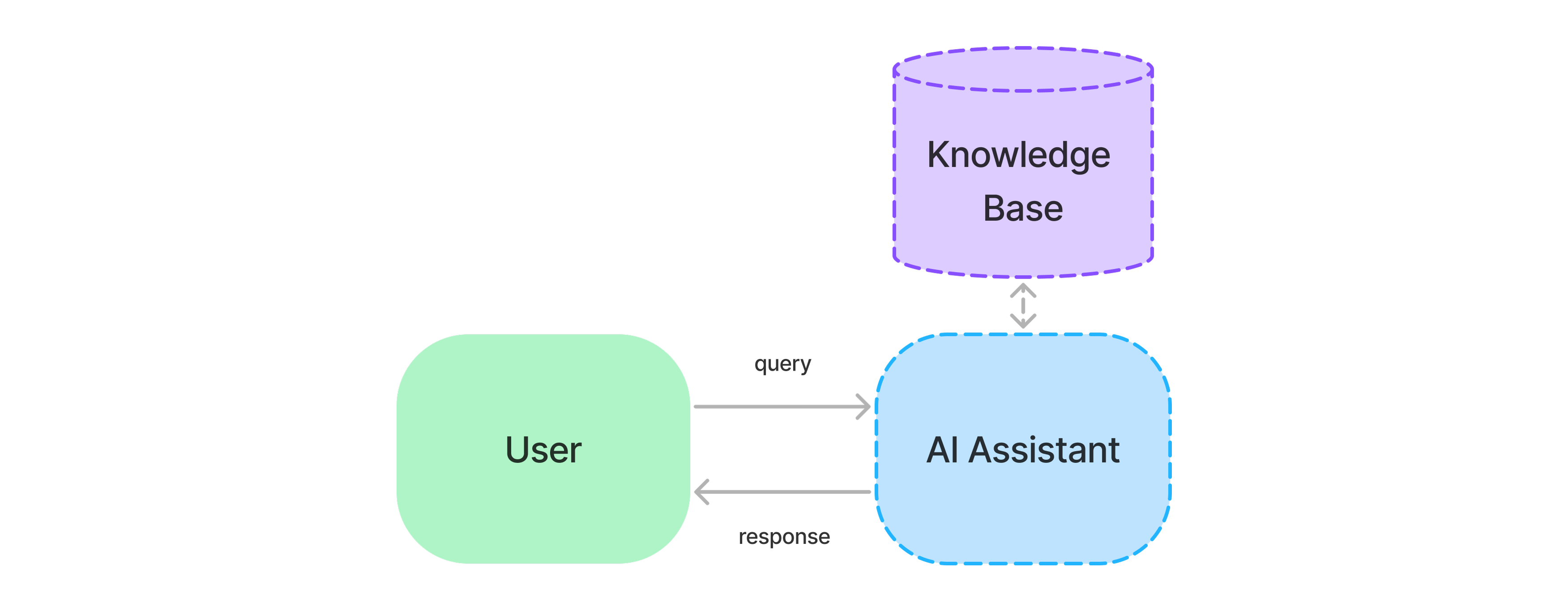
Figure 1: LLM limitations commonly necessitate incorporating external data into our AI Assistants.
A knowledge base is a generic term for a repository of external information that the system can query to find relevant context. In most traditional approaches, this was done with key words in the documents and additional statistics on the content of the underlying information. This makes sense for things like search engines, where key terms are applied to find the right document, but most LLM interactions take the form of a specific question with an equally specific answer. This means that looking up key words may not necessarily align to the right documents or may return very large documents that won’t fit into the context window of the LLM. Ultimately, the context of those documents or more specifically, the context of chunks within those documents is more important.
This brings us to the concept of semantic similarity. Unlike lexical similarity, which focuses on the exact match of words, semantic similarity assesses how closely the underlying concepts or ideas match. For instance, the phrases “the cat is on the mat” and “a feline rests atop a rug” are lexically different but semantically similar, since they convey the same idea.
To integrate semantic similarity into a RAG workflow, we use an embedding model to convert text into embedding vectors—fixed-dimension numerical representations that capture the meaning of the text. To better preserve context, we typically divide documents into smaller, logical “chunks” and generate an embedding vector for each chunk using the same model (Figure 2).
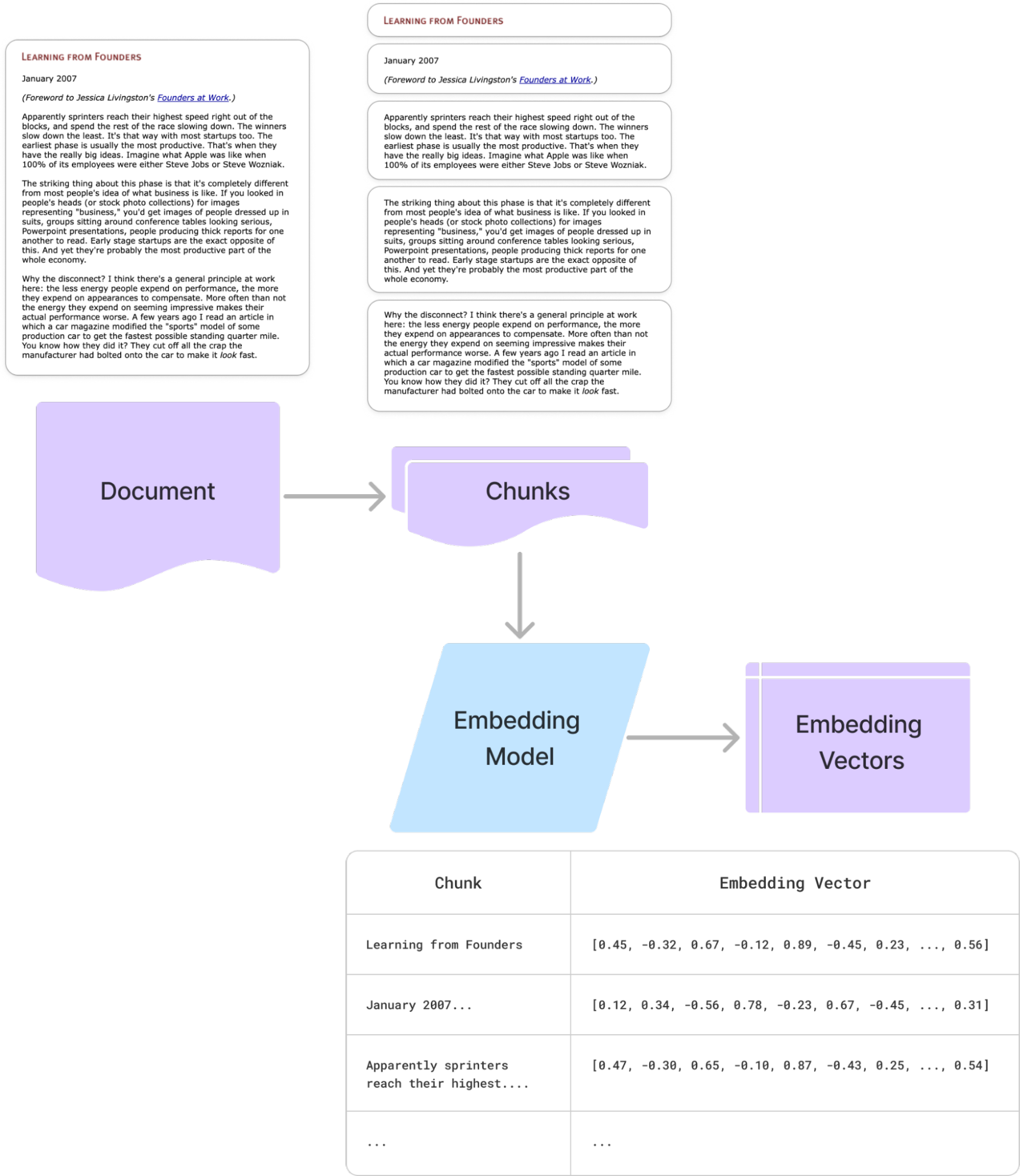
Figure 2: Text embedding process. Sample document text is from Paul Graham’s essay “Learning from Founders.”
With embedding vectors for each chunk, we can compare an embedding vector for the query with all the chunk embedding vectors to figure out which ones are the most semantically similar, giving us our “retrieved context.”
Why not just use the LLM’s internal embeddings instead of an embedding model? While LLMs inherently use embeddings, querying them directly is computationally expensive. Instead, specialized embedding models (like OpenAI’s Ada, Cohere’s Embed, or open-source options like BGE or SBERT) are used because they can efficiently generate high-quality embeddings without the overhead of a full LLM.
Once we generate embedding vectors for our knowledge base, we need an efficient way to search them. Comparing a user’s query embedding to every stored chunk would be too slow, especially at scale. This is where vector databases come in.
Vector databases store precomputed embeddings and allow for fast similarity searches. When a user submits a query, we:
This process ensures that the LLM has the most relevant external data before producing an answer.
Figure 3 illustrates how data flows through the knowledge base construction (ingestion) and query processing (inference) stages. Notice how both processes rely on the same embedding model and vector database to ensure consistency across ingestion and retrieval.
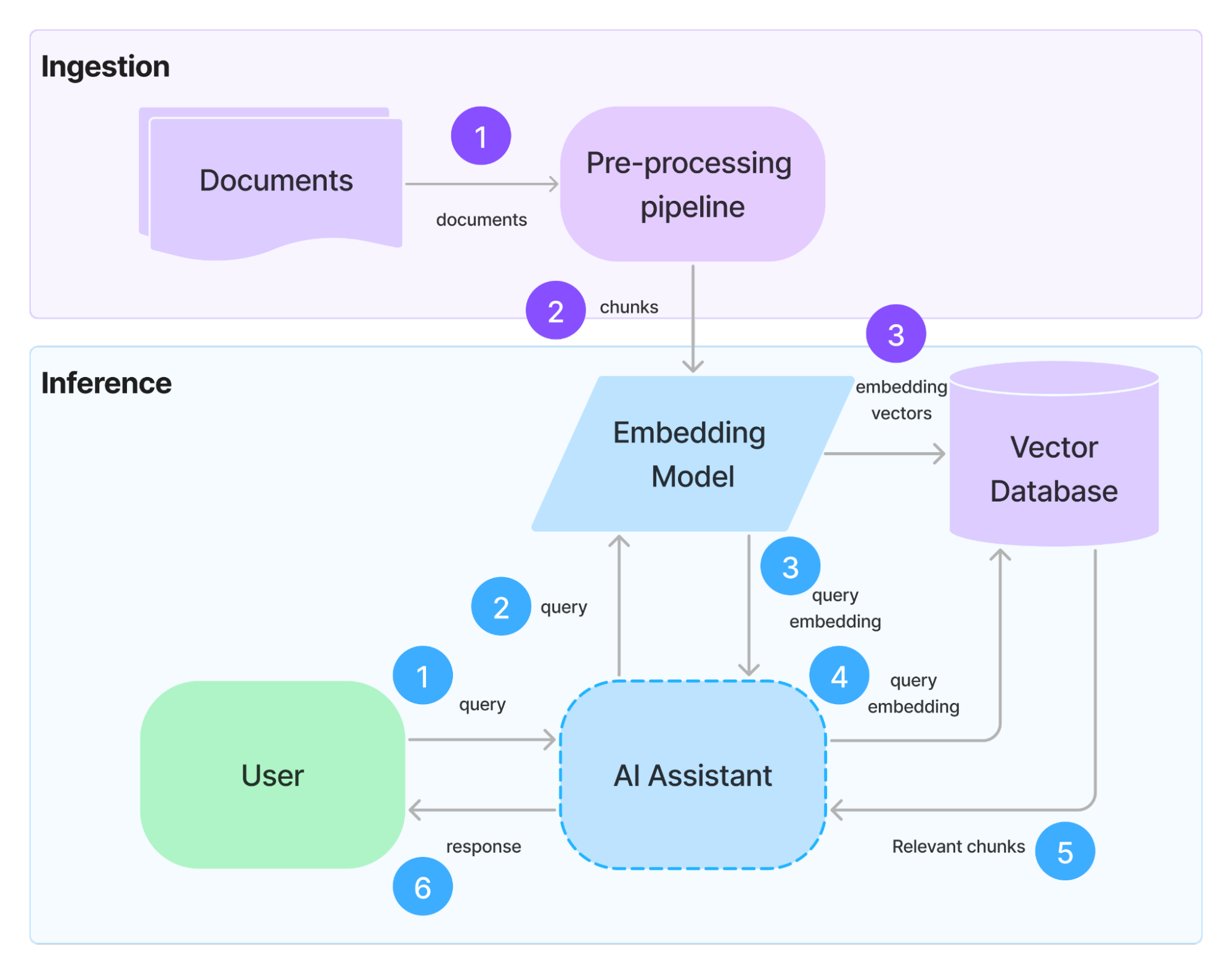
Figure 3: Knowledge base construction process (Ingestion), shown in purple. Query process with a Knowledge base process (Inference) shown in blue. Numbers indicate the ingestion and inference steps in order respectively.
Vector databases are a broad topic with many different vendors, indexing strategies, and optimizations. While we won’t cover them in depth here, understanding how they impact retrieval speed and accuracy is important for optimizing a RAG system. This comparison may be useful in understanding some of the differences.
With a knowledge base in place, the final piece of a RAG system is the retriever—the component responsible for finding and delivering relevant information. The retriever acts as the bridge between a user’s query and the LLM, ensuring that only the most relevant chunks from the vector database are passed along.
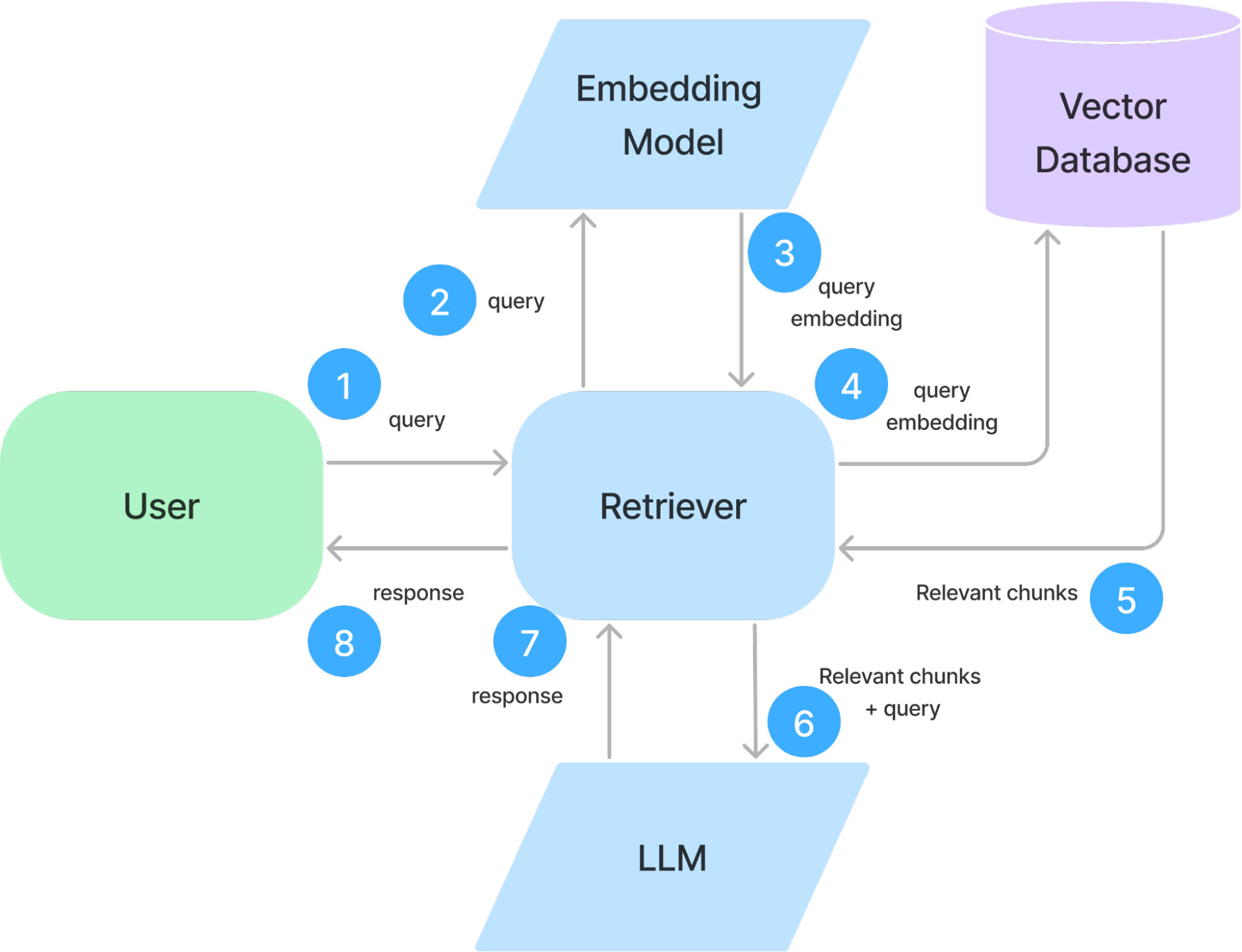
Figure 4: Data flow through the retriever during inference.
When a user submits a query, the retriever follows these steps (Figure 4):
With the retriever in place, we now have a functional RAG system. However, there are several ways to refine and improve this architecture. For example:
In the next section, we’ll explore how to enhance retrieval accuracy, improve response quality, and address common RAG challenges.
While RAG improves LLM reliability, real-world applications often expose its limitations. Retrieval can still return irrelevant, incomplete, or even incorrect information. Additionally, issues like chunking errors, poor embedding quality, and missing context can impact response accuracy. To build a high-quality system, we need advanced techniques that refine how data is processed, retrieved, and used. Here we’ll list out a few of the techniques used to alleviate these pain points.
Retrieval is a critical part of a RAG system, but not all retrieved chunks are equally useful. Some may contain the exact information needed to answer a query, while others might be only tangentially relevant or even misleading.
One approach to refining retrieval is ranking and re-ranking. When a query is processed, the retriever often returns multiple potential matches, but they aren’t always sorted in the most useful order. A ranking or re-ranking model evaluates these retrieved chunks, scoring them based on their relevance to the query. Higher-ranked chunks are prioritized and sent to the LLM first, improving the likelihood that the response is accurate and well-supported by the knowledge base (Figure 5).
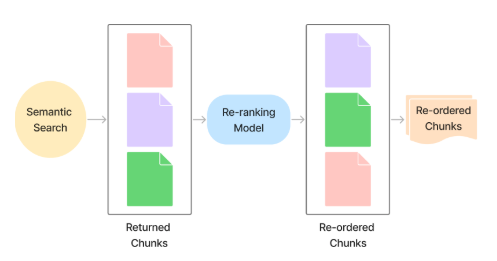
Figure 5: Re-ranking model used to re-order the results returned by the semantic search. Adapted from the original diagram here.
Another challenge in retrieval is that vector-based search doesn’t always align with how users phrase queries. While embeddings capture the semantic meaning of text, user queries are often more literal. For example, if someone asks, “What day of the week is Easter in 2025?” a pure vector search may retrieve documents discussing past Easter dates rather than answering the specific question. To bridge this gap, hybrid search methods combine vector-based retrieval with traditional keyword-based search. This approach balances semantic similarity with exact keyword matches, improving the precision of retrieved documents and ensuring that the most relevant data is surfaced (Figure 6).
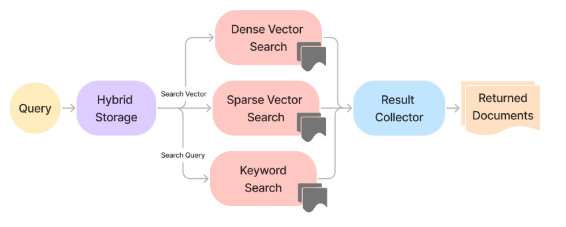
Figure 6: Hybrid Three-Way Search diagram. Adapted from the original diagram here.
Beyond retrieval techniques, data quality is one of the most critical factors in RAG performance. If the knowledge base contains poorly formatted, incorrect, or redundant information, retrieval can surface misleading or irrelevant chunks, negatively affecting the LLM’s responses. Issues such as bad chunking strategies, ambiguous wording, and improper segmentation can distort embeddings and reduce retrieval accuracy. Addressing this usually centers on preprocessing techniques like better text segmentation, noise reduction, and human-in-the-loop validation to ensure high-quality information is stored and retrieved.
However, even with well-structured data, retrieval systems aren’t static—they need to adapt and improve over time. One of the biggest challenges in RAG is incorporating feedback to refine chunking, retrieval, and response quality. Improving RAG requires continuous feedback mechanisms that monitor performance and adjust retrieval processes accordingly.
Several key approaches help refine retrieval quality over time:
A recent paper, “Seven Failure Points When Engineering a Retrieval Augmented Generation System,” outlines some of the most common pitfalls when designing and tuning RAG architectures. We’ll explore these challenges—and how to address them—in a future blog.
While traditional RAG systems are designed to retrieve and process text, many real-world applications require working with non-text data such as PDFs, images, tables, charts, and even audio files. Relying solely on text-based retrieval can limit the effectiveness of RAG systems, especially when crucial information is stored in structured formats or visual elements. To address this challenge, advanced techniques are used to extract and incorporate non-text data into the retrieval pipeline.
One common method is Optical Character Recognition (OCR), which is essential for processing scanned documents and images containing embedded text. OCR extracts readable text from these sources, allowing them to be indexed and retrieved just like standard text-based documents. However, OCR alone is typically not enough for complex documents that contain structured elements like tables, diagrams, or multiple columns of text. In these cases, structured metadata and layout-aware processing techniques help preserve the original context and format, ensuring that retrieved information remains meaningful.
For even more advanced retrieval capabilities, multimodal embeddings are used to represent not just text, but also images, charts, and other visual components. These embeddings allow RAG systems to search for relevant content across different data formats, making it possible to retrieve not only text passages but also supporting diagrams or figures that provide additional context. Figure 7 illustrates a multi-modal RAG ingestion pipeline, where documents are parsed based on their content type, extracting relevant information from both text and non-text components.
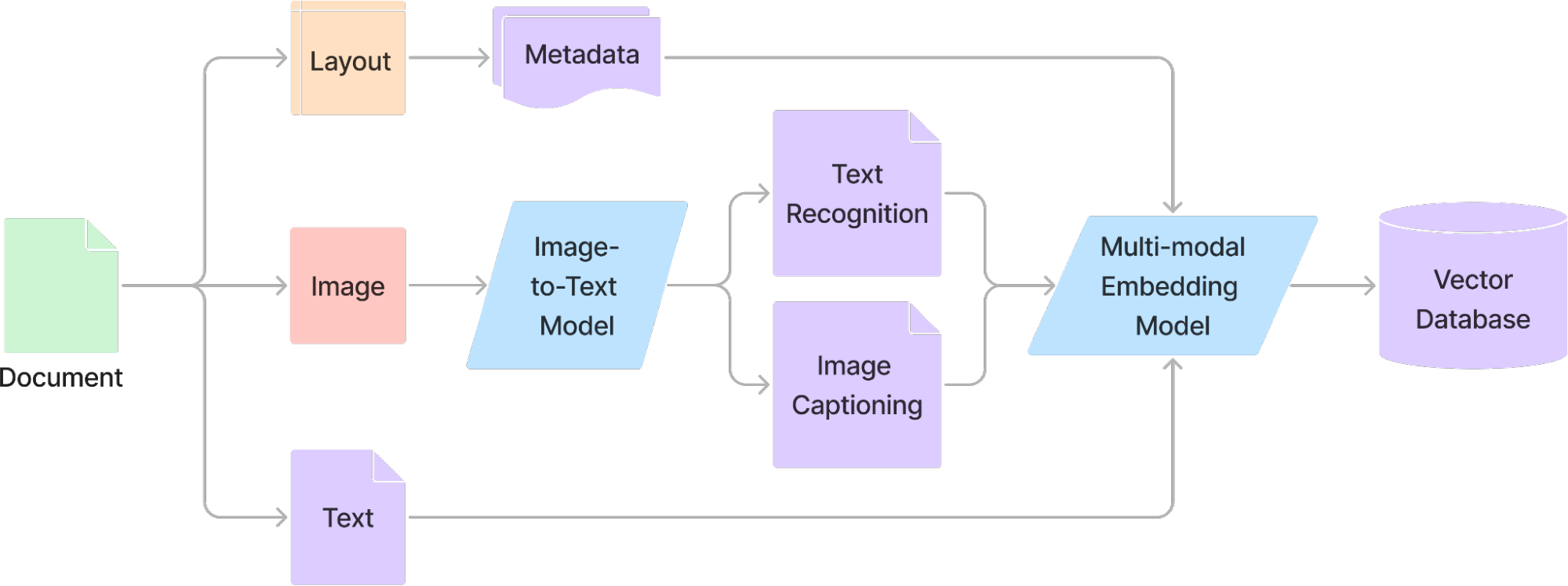
Figure 7: Multi-modal RAG ingestion pipeline. Documents are parsed for text, layout, and images, then sent accordingly to extract relevant information from each component. Adapted from the original diagram here.
While traditional RAG systems enhance LLMs by providing relevant external knowledge, they remain passive in how they retrieve and use information. Retrieval happens once per query, and the system pulls relevant context and feeds it to the LLM to generate a response. Agentic RAG expands this concept by enabling AI systems to observe, reason, and act dynamically, rather than simply fetching and passing along information. It introduces an iterative approach, where the AI can refine its own retrieval process, request additional context, and validate responses before returning an answer.
For example, instead of simply retrieving a set of documents and responding, an agentic RAG system could:
This ability to dynamically adjust retrieval strategies makes agentic RAG especially useful in scenarios where a single retrieval pass may not be enough, such as research-heavy tasks, decision support systems, or interactive AI assistants that need to ask clarifying questions. These systems are also commonly extended with tools, like search engines or API calls to systems to add additional observations to the context. An overview of Agentic RAG is shown in Figure 8.
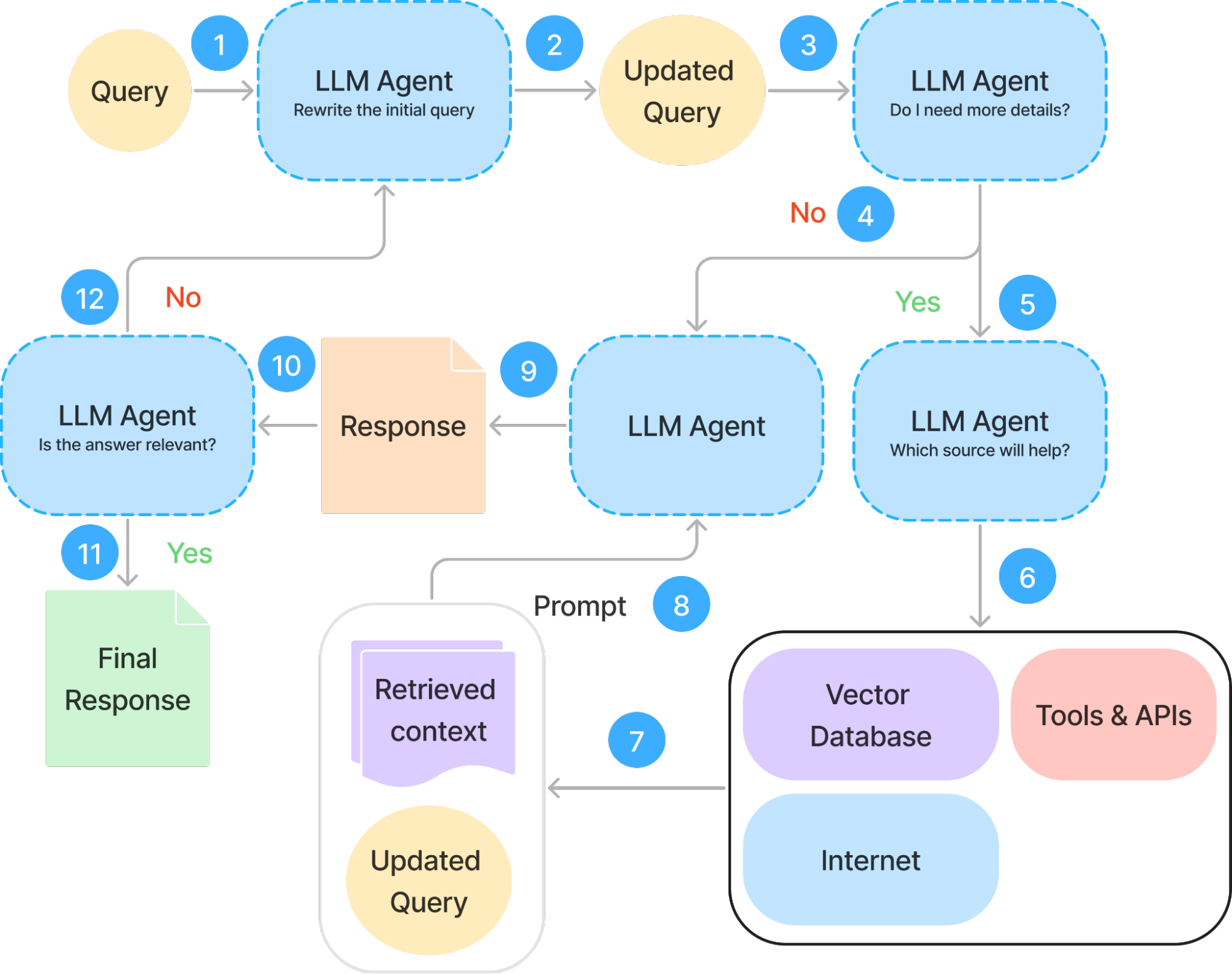
Figure 8: Inference process for Agentic RAG. Adapted from the original diagram here.
While agentic approaches sound compelling, building controllable and reliable agentic systems remains a challenge. Introducing more decision-making steps increases complexity, and without careful design, agents can become unpredictable or inefficient. Despite these hurdles, agentic RAG offers a promising evolution of retrieval-augmented systems, pushing AI beyond static information retrieval toward adaptive, context-aware reasoning. As research in this area progresses, we can expect to see even more sophisticated agentic approaches that improve both the accuracy and depth of AI-generated responses.
RAG is a powerful technique for enhancing LLM performance, but as we’ve explored, implementing it effectively requires ongoing refinement. From ranking and retrieval optimization to handling complex queries and multimodal data, each challenge highlights the need for continuous improvement in how we manage and retrieve information.
One of the most critical areas for improvement is incorporating human feedback into the RAG pipeline. No matter how advanced retrieval techniques become, errors in chunking, ranking, or context selection can introduce misinformation and reduce accuracy. By integrating feedback loops, error detection, and adaptive learning methods, we can create RAG systems that better serve real-world applications.
In our next post, we’ll dive into how human feedback can refine retrieval, improve ranking, and reduce errors in generated responses. Stay tuned!

Learn how to prioritize weak responses, streamline human-in-the-loop review, and use feedback to iteratively improve your retrieval, prompts, and models.

RAG is transforming how businesses use AI, but without human oversight, its accuracy and reliability suffer. This blog explores the biggest challenges in RAG implementation and how human expertise improves data quality, retrieval relevance, and AI-driven decision-making.
