Reinforcement Learning from Verifiable Rewards

Nikolai Liubimov
CTO
CTO
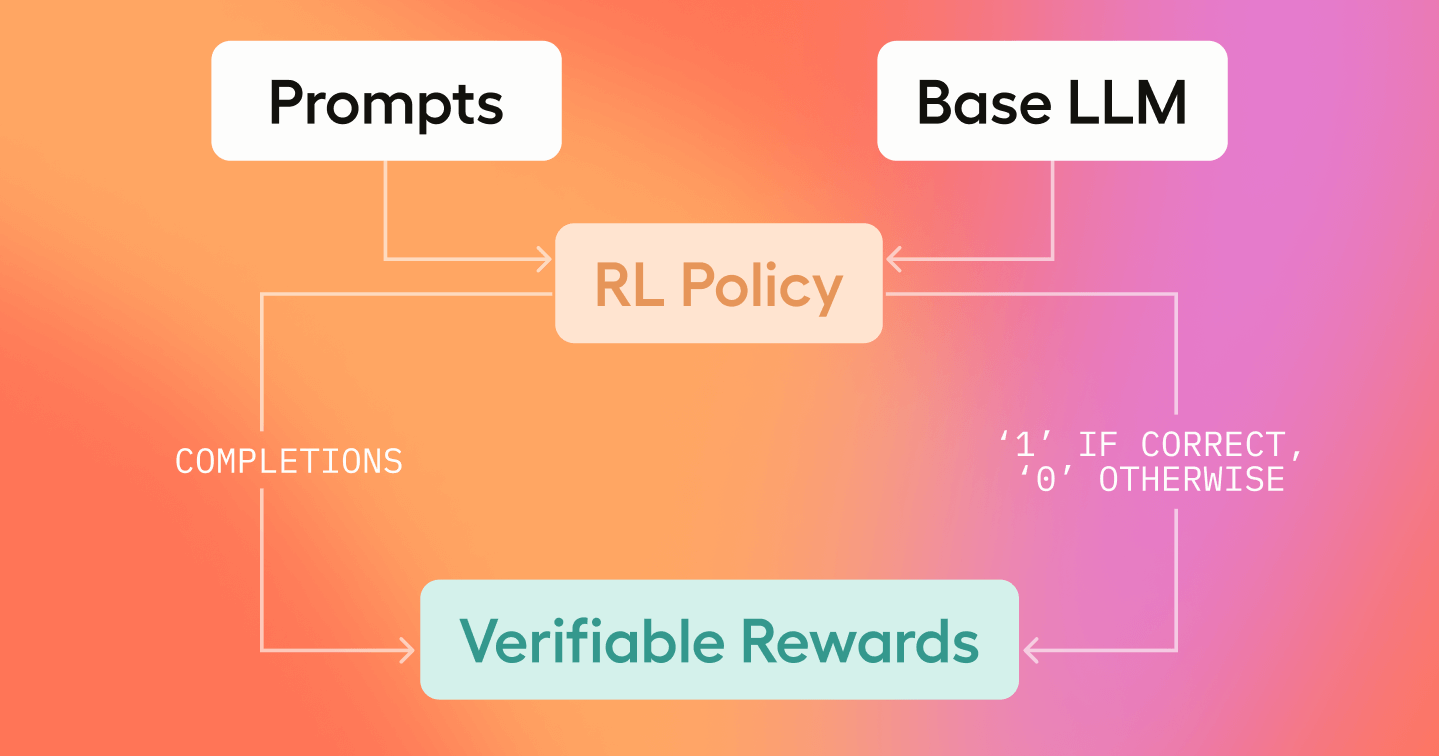
Reinforcement Learning with Verifiable Rewards is among the leading training strategies for injecting learning signals into LLMs, successfully employed by models such as DeepSeek R1 and Tülu 3. In a nutshell, Verifiable Rewards are simple functions that provide a clear-cut, binary ground truth signal - typically a “1” (correct) or “0” (incorrect) - to indicate whether a model’s output meets a predefined correctness criterion.
Unlike traditional, neural reward functions utilized in RLHF, verifiable rewards offer several advantages:
Their binary nature ensures a direct, bias-free objective connection to ground truth, making them ideal for precision-critical tasks like mathematical problem-solving and code execution.
Verifiable rewards provide a quick and easy way to design robust RL environments, allowing subject matter experts to establish clear correctness criteria without deep machine learning expertise. Their explicit nature facilitates automated evaluation, minimizing reliance on human judgment and ensuring efficient and scalable integration into reinforcement learning pipelines.
Because verifiable rewards rely on strict, rule-based evaluations rather than learned approximations, there is little room for the LLM to “hack” the system. With a binary indicator, the model receives no partial credit for outputs that only superficially meet the criteria.
In essence, verifiable rewards serve as a straightforward “yes/no” gate that informs the learning algorithm whether a particular output meets the necessary conditions, thereby streamlining the training process by providing unambiguous feedback.
Here are a few simple examples of verifiable rewards:
For tasks involving numerical or symbolic computations, verifiable rewards check the accuracy of the mathematical solution.
Example: Using the GSM8k dataset, which is made up of grade school math word problems, an LLM generates a step-by-step solution to an algebra problem and the final result was collected after four hashtag symbols “####”. Then a string-matching algorithm is used to compare with the ground truth answer. If completely correct, score 1 point; if the format is correct, score 0.1 points; if the format is incorrect, score 0 points.
For more on the mathematical correctness example, check out this paper from DeepSeek or this documentation from the package Verl, available in Python.
In scenarios where LLMs are used to generate code, verifiable rewards are derived from executing the code and comparing the outcome to an expected result: unit tests, exceptions etc.
Example: In the multi-turn code synthesis setup, verifiable rewards can be assigned based on the execution results of generated code against test cases. The reward function evaluates correctness at the end of each episode as following:
For more on the code execution example, see this 2024 paper.
These rewards evaluate whether the LLM output strictly adheres to a given set of instructions or guidelines. Typically, it can be done via a simple string-matching.
Example: In the model response, one of the following criteria should be satisfied:
def strict_format_reward_func(completions, **kwargs) -> list[float]:
"""Reward function that checks if the completion has a specific format."""
pattern = r"^<think>\n.*?\n</think>\n<answer>\n.*?\n</answer>\n$"
responses = [completion[0]["content"] for completion in completions]
matches = [re.match(pattern, r) for r in responses]
return [1.0 if match else 0.0 for match in matches]
For more on the instruction following and formatting example, see this paper on instruction following in LLMs and this paper from DeepSeek.
Verifiable rewards can also extend to other domains, such as:
Moreover, scaling high-diversity RL environments by carefully designing verifiable criteria can lead to eliciting high-quality LLM reasoning regarding specific problems and domains, as well as collecting and distilling reasoning traces into smaller, more efficient specialized models.
Designing a verifiable reward function requires expert knowledge, domain expertise, and structured data interfaces. This ensures reinforcement learning (RL) systems optimize for measurable, high-quality outputs while avoiding biases and misalignments. The following steps outline a robust approach:
By following these steps, RL-based systems can achieve high performance while maintaining transparency and reliability in decision-making.

Learn the data curation and human supervision techniques that we believe are crucial to DeepSeek’s success by examining technical reports from DeepSeek-R1, DeepSeek-V3, and its predecessors.
RLHF has enabled language models trained on a general corpus of text data to be aligned with complex human values. This article details how you can train a reward model for RLHF on your own data.


A practical framework for turning AI metrics into clearer decisions about what to fix, ship, and scale.
