How Yext Takes Its AI-powered Search Engine to New Heights With Label Studio
In Conversation With
Vera Dvorak
Machine Learning Operations Manager
Michael Misiewicz
Director of Data Science
525
%
Increase in capacity to take on labeling projects
2-4
x
Annotators complete 2-4x more per day
100
%
Reduction in the amount of data discarded
3
x
Labeling tasks the software could perform increased 3x
Introduction
What if there was an intuitive, Google-like search experience that allowed customers to get direct answers to their questions on your organization's website, app, or workspace? Since 2006, software company Yext has been using differentiated technology, data, and AI modeling to bring those capabilities to thousands of businesses worldwide.
Yext provides a suite of solutions, the Answers Platform, that helps organizations manage their online presence and deliver exceptional digital experiences everywhere their customers, employees, or partners look for information. Its flagship product is Search, an NLP-driven search engine that companies can add to their digital properties to answer user questions in real-time.
To expand the reach of its Search product internationally, Yext needed to train the NLP models powering Search in languages other than English. And that’s where Yext hit a roadblock: its existing data labeling software couldn’t scale to meet its ambitions. The resulting inefficiencies led to lost data and threatened Yext’s ability to train new AI models.
So, the company switched to Heartex’s Label Studio Enterprise.
Soon, Yext’s Data Science department and Machine Learning Operations/Annotation team saw 2-4 times rise in annotator efficiency, increased their project capacity by 250%, and reached more markets around the world.
The Anatomy of Yext’s Data Labeling Team
At a high level, the data labeling process at Yext involves two teams: Data Science and MLOps/Annotation.
The Data Science department, led by Michael Misiewicz, is responsible for building the algorithms that power many of the company's products as well as applying AI and ML to operational problems. They rely on timely access to labeled and validated data to continuously retrain models and analyze model accuracy.
The Machine Learning Operations/Annotation team includes all of the annotators and is responsible for labeling the data used to train models. Yext’s annotators are a mix of internal team members and contractors distributed all over the world — currently, there are annotators who label data in English, Japanese, German, Italian, Spanish, and French.
Vera Dvorak, Machine Learning Operations Manager, is the point of crossover between the two teams. Vera is a formal linguist who communicates with both the data science team and the annotators, but especially the annotators. She manages the process of collecting and properly labeling the data by providing clear annotation guidelines and working closely with the annotators to review and troubleshoot.
The Problem
Yext’s Existing Labeling Solution Wasn’t Scalable
Before the company switched to Label Studio, the data science and annotation teams at Yext were using a different well-known open-source labeling tool. This tool had been successful in helping the team create Yext’s signature line of NLP products, but it wasn’t keeping up as Yext’s strategy matured.
Extending the typology of labeling tasks and tackling other languages meant introducing additional people, projects, and processes to the labeling software. When it came to handling the load, the previous tool fell short thanks to three high-level issues: slow manual processes, a lack of visibility, and limited validation options.
Previous Tools Relied on Slow Manual Processes
With their old data labeling tool, Yext’s data engineers had to rely on scripts, manual file imports, and other cumbersome processes to perform basic tasks like querying their warehouse or assigning work to annotators. As a result, valuable engineering time and expertise were lost to tedious manual work.
Meanwhile, the annotation team also struggled with slow processes. Sometimes, the old tool duplicated or even triplicated their data, and there was no way around performing manual comparisons to check for copies and discord in assigned labels.
Limitations in User Roles Led to Poor Visibility
Everybody was an admin on the old tool; there was no way to distinguish between labelers, reviewers, and other user roles. In consequence, it was hard to keep track of who was assigned to which project and what each annotator was working on. The visibility into the annotators’ work was so poor, in fact, the tool was unable to flag an annotator who didn’t show up to work for two weeks, but continued billing.
When I joined the team, I immediately sensed lots of annotators’ frustration around how to determine accurate labels.
Vera Dvorak
Machine Learning Operations Manager
Poor visibility also impacted Vera’s ability to troubleshoot and collaborate with the annotators. “When I joined the team, I immediately sensed lots of annotators’ frustration around how to determine accurate labels.” she tells Heartex. There was a Slack thread where annotators raised questions, but the responses were spotty since it created another channel to monitor and not all annotators were following it. It was also difficult to search and find old threads to discover questions and answers that had already been addressed. “Whereas in Label Studio, you can search for similar or identical language data and organize them into tabs, you can easily mark things for discussion, and you can always go back to your ground truth examples for assurance.”
Validation Functionality Was Limited
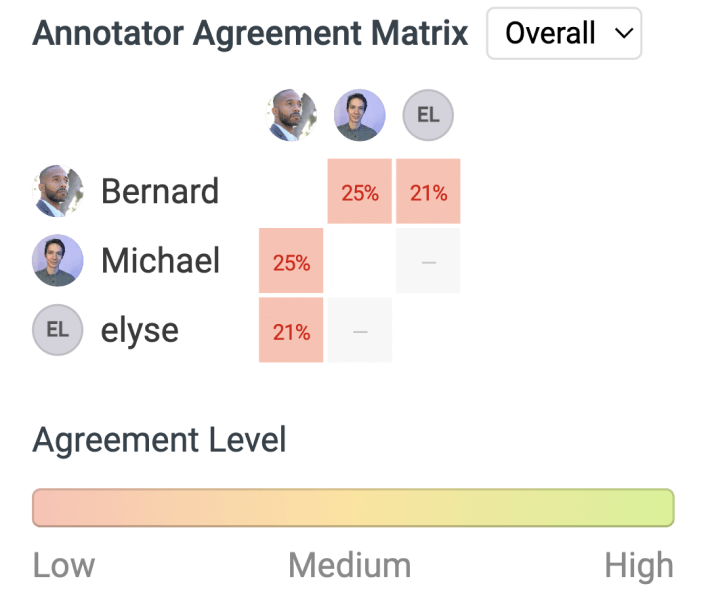
More troubling still, the team’s ability to validate labeled data quality was severely constrained by their old tool. The only validation method the team could use was blind consensus, wherein two or more annotators were assigned the same item in their labeling queue, so the data scientists could spot inconsistencies when they compared the annotated after exporting them.
When annotators disagreed, there wasn’t a user-friendly way to explore the discrepancy and put the data back into the pipeline. So the team had no choice but to discard the data completely.
As a result, the team lost an average of 40% of their labeling data on every project, severely impeding their capacity to train and retrain the ML models. To compensate, the team had to add a significant amount of time and data to each project.
What’s more, the broad-strokes approach to data quality meant the team was discarding the kind of data that really improve a model. The more an NLP model learns how to interpret language ambiguities and vagueness that often cause annotator disagreement, the more natural and informative its responses become.
You expect your labeling software to have a good way to dig deeper into these types of data. That was one of the driving forces behind finding a better labeling platform.
Vera Dvorak
Machine Learning Operations Manager
“You want to cover the more ambiguous data and tricky, complicated examples as well,” Vera tells us. “You expect your labeling software to have a good way to dig deeper into these types of data. That was one of the driving forces behind finding a better labeling platform. If you have a proper review process when annotators disagree, you can actually get those data back into the training pipeline.”
The Solution
Yext Differentiates Its Data With Label Studio
When Yext hired Vera, it had six projects based on three different labeling tasks in the old labeling platform (three in English, two in Japanese, one in Spanish) and another complex English labeling project in a separately created internal tool. After switching to Label Studio, it now has 21 projects across six languages—a 250% increase in the number of projects the team can take on. That number is not final as they are continuously adding new kinds of labeling tasks, stemming from the Answers Platform needs, and extending the coverage to other languages. The drastic improvement in productivity can be attributed to higher annotator confidence, better team governance, and greater flexibility with the new platform.
250
%
Increase in capacity to take on projects
Higher Annotator Confidence Improves Accuracy
Now that Vera has more control over the labeling and review process, the annotators tell her they feel more confident when assigning labels. Since they now have a productive way to ask questions and resolve issues, the annotators spend less time waiting for answers or labeling data intuitively and wondering whether they’re on the right track. They can mark items for discussion and navigate to a tab that contains their full list of marked items. And on her end, Vera can see all the marked items in one place.
The annotators also have the option to split tasks into smaller pieces, based, for example, on a particular business domain or metadata associated with the primary data. This lets them break up monotonous work with more challenging short-term projects, so they don’t get bored or lose focus, while Label Studio’s setup still ensures comprehensive coverage of the task.
Annotators and reviewers have a clear process and functionality to review annotator disagreements. Where 40% of data was previously thrown out due to annotator discrepancies, the Label Studio agreement matrix and ability to assign tasks for labeling overlap and review has allowed the team to reclaim all data that previously would have been discarded. Instead of relying on “blind consensus” as in the case of the previous software, the team now relies on a two-phase quality verification. First, the same data are assigned for annotation to at least two annotators. Utilizing Label Studio functions, Vera determines the tasks with less than 100% agreement and the annotators are asked to go over them again and reach consensus whenever possible (or escalate them for a team discussion). Second, some or all of the labels go through a round of reviews by more experienced annotators who can either accept the original labels as they are or fix them and then mark them as accepted. More complex and more accurate data that Yext gains this way result in more performant models.
Better Team Governance Increases Productivity
Vera manages a team of primarily external contractors to annotate their data, which she can scale up or down based on the projects in her pipeline. Label Studio gives her a centralized platform and governance to manage the contractors, including their access to sensitive business data, visibility into their performance, and pulling reports for administrative processes such as billing.
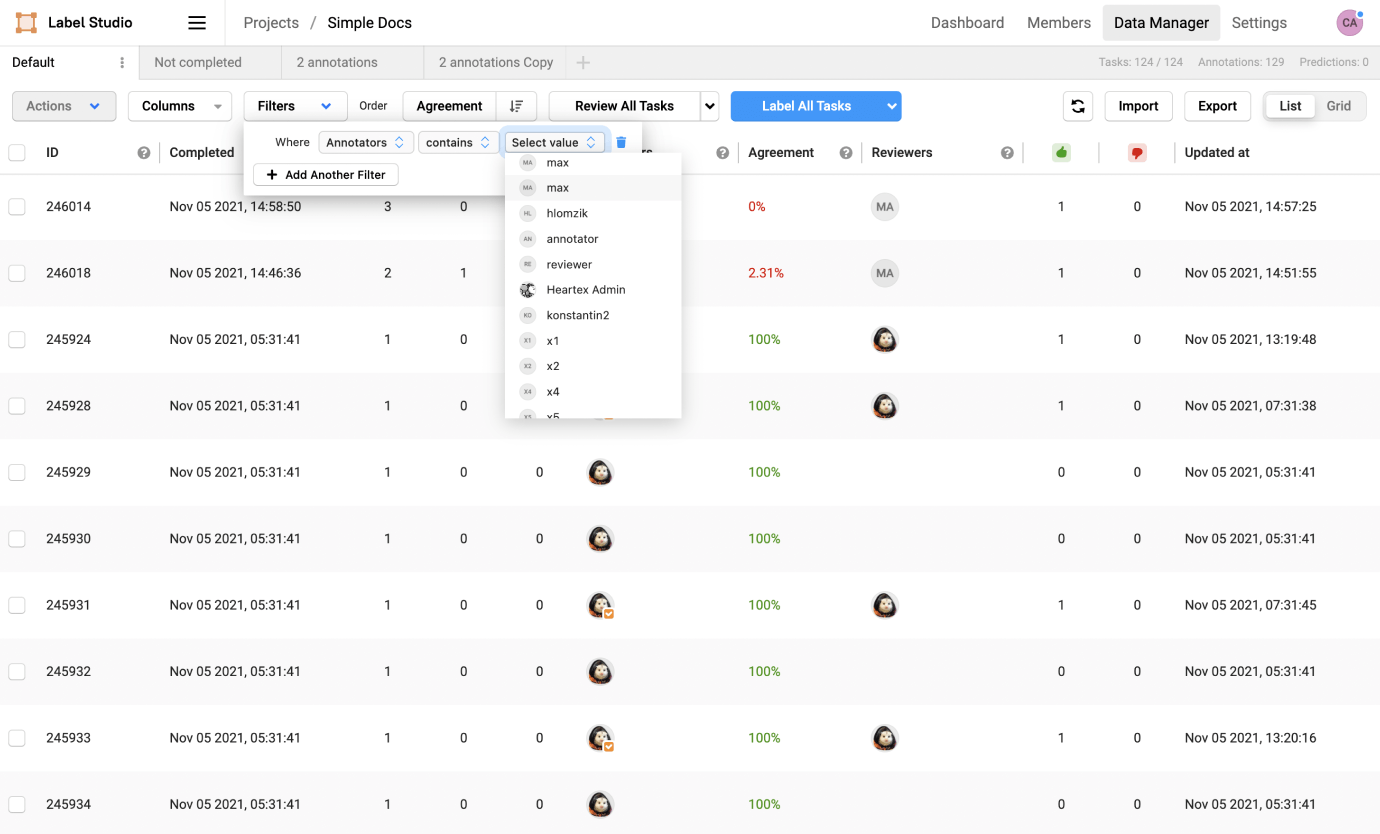
The concept of workspaces, projects, and user roles in Label Studio Enterprise help the team collaborate more effectively. Now everyone has the visibility they need to perform their job functions, but annotators only have access to the workspaces and projects to which they are assigned. There’s a Data Manager view that allows Vera to quickly scan through data, both labeled and unlabeled, assign tasks, configure a review process, and monitor progress. The data science team has full visibility into all the datasets in one view, and they have the power to search, sort, and filter the training data before exporting, improving the team’s ability to capture insights.
As the operations and annotation team manager, Vera has visibility into the performance of each individual annotator, whether they are a full-time employee or a contractor billing just a few hours every week. This includes their hourly and daily throughput, as well as accuracy and reliability of their labeling. Having a complete view of these secondary data helps her distribute work, identify and correct performance issues, and increase team’s overall productivity.
50
%
Number of annotators could be reduced by 50% without compromising the project
As a result of their more efficient review process and more focused engagement, the annotators went from labeling around 300 queries per day with the old software to labeling anywhere between 600 and 1,200 queries per day with Label Studio. Consequently, the number of annotators on any given English project could be reduced by 50% without compromising the project’s continuous growth.
Before Label Studio, it took the team an average of 3-4 weeks to create a dataset large enough to train a model. Now it takes them 1-2 weeks.
1-2 weeks
The team saves an average of 1-2 weeks to create a dataset large enough to train a model
One of the major benefits of Label Studio is that it supports all data types in one platform, which means you can manage all of your labeling projects with common workflows, reporting, and governance. It was a big relief when Yext data scientists could say farewell not just to a previous limited software but also to a buggy labeling app that had been created in-house for one specific type of annotation—and they could recreate all of the previous labeling tasks “under one roof” in Label Studio Enterprise. Moreover, Label Studio expanded the number of use cases the annotation team could support and opened the door to creating new custom labeling interfaces, tripling the number of distinct annotation types managed in Label Studio versus the previous software. In addition to named entity recognition, entailment, and span-level answers, the team was able to add QA creation, search quality evaluation, NLP filter evaluation, epsilon optimization review, pre-labeled numeric range validation, document retrieval analysis, and auto-matching validation.
Which feature has made the biggest difference in improving the team’s efficiency? For Michael, Yext’s Director of Data Science, it was Label Studio’s user-friendly templates for structuring queries and enriching them with metadata.
“The issue we were having with some of the text-based systems in the past was that we had to manually write text strings,” Michael says. “So, if you wanted to say, ‘Here’s a search query that somebody typed into a website, and this was the list of results,’ we had to do all this cumbersome text formatting. The templating language that Label Studio offers is really powerful and saves us time.”
The team also notes that Label Studio’s user-friendly, concise interface is a highlight for them. No more do they have to scroll through screens and complicated menus just to find what they need, and the platform runs smoothly.
“It’s really snappy now, even with hundreds of thousands of data points in a project or across workspaces,” says Michael.
It’s really snappy now, even with hundreds of thousands of data points in a project or across workspaces.
Michael Misiewicz
Director of Data Science
Outcome
Label Studio Continues To Improve Yext’s AI Models
Conclusion
Up Next for Yext: A Worldwide Market
Now that the team can collaborate efficiently at scale, they can take on new opportunities. Yext’s AI-powered Search product currently supports advanced features in six languages, and the team would like to expand to many more.
Internationalization would be a major differentiating factor for Yext because there are a number of low-resource languages that aren’t supported by search engines, but hundreds of millions of people who speak them. That’s a powerful market need—one that allows Yext to make exciting and ambitious plans for the future.
“Yext is the ‘Answers Company’, because we believe that there is no query that cannot be answered properly. And we aim to make that a reality for each of our customers,” says Vera. “With help from Label Studio, I can also confidently say that there is no piece of language data that cannot be labeled properly.”
With help from Label Studio, I can also confidently say that there is no piece of language data that cannot be labeled properly.