Label Studio Enterprise
Infrastructure to scale human judgement
Train, Benchmark and Evaluate AI. Label Studio sits at the center of your workflow, connecting data, models, and human judgment into a continuous improvement loop.
Train, Benchmark and Evaluate AI. Label Studio sits at the center of your workflow, connecting data, models, and human judgment into a continuous improvement loop.
Every team's label schema, review flow, and evaluation rubric is different. Label Studio gives you advanced tools to create interfaces perfectly aligned to your data and use case.
The new interface agent in Label Studio Enterprise will quickly build any interface shaped to your data and evaluation criteria.
Quickly configure annotation interfaces with pre-built tags for all common data scenarios, or build advanced interfaces in React.
Explore Templatesdef push_tasks(tasks: list[dict]) -> list[int]:
"""Import tasks into the project; returns the created task IDs."""
result = ls.projects.import_tasks(id=PROJECT_ID, request=tasks)
print(f"Imported {len(tasks)} tasks into project {PROJECT_ID}")
return result.task_ids if hasattr(result, "task_ids") else []
from braintrust import init_project
project = init_project(name="customer-support")
experiment = project.experiments.fetch("v3-eval")
records = experiment.fetch_all()
scored = [r for r in records if r.scores.get("accuracy")]
print(f"Retrieved {len(scored)} scored eval records from Braintrust")
from databricks import sql
with sql.connect(server_hostname=HOST, http_path=PATH, access_token=TOKEN) as conn:
cur = conn.cursor()
cur.execute("SELECT id, transcript FROM main.support.tickets LIMIT 1000")
rows = cur.fetchall()
print(f"Retrieved {len(rows)} support transcripts from Databricks")
API, Python SDK, and webhooks let you create projects, stream predictions, and trigger training, active learning, and evaluation workflows in real time.
Sync data from any storage and connect any model to power AI-assisted labeling, benchmarking, and continuous model evaluation.
Make the highest use of your unique expertise and novel datasets as you train, benchmark, and evaluate AI in one common environment.
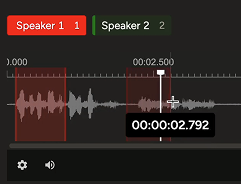
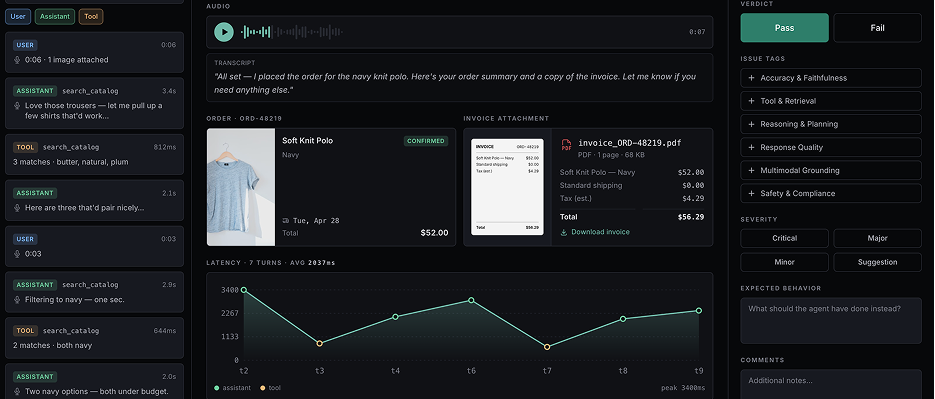
custom, multimodal UI to capture human judgment
Full-scale infrastructure used by millions