AI Benchmarks
Evaluate AI Models with Custom Benchmarks
Turn model evaluation into clear, repeatable metrics that map to your unique business outcomes.
Turn model evaluation into clear, repeatable metrics that map to your unique business outcomes.
why custom ai benchmarks matter
LLM leaderboards and off-the-shelf benchmarks provide useful reference points, but they rarely reflect the unique challenges of your business. HumanSignal makes it easy to design custom benchmarks that align with your specific domain, data, and success metrics.

Expose model blind spots early, preventing costly errors in production.

Compare models side by side using your data, not someone else’s leaderboard.

Track improvements over time and link model performance directly to business outcomes.

Demonstrate quantifiable, transparent evidence that your AI systems meet internal standards and compliance requirements.
AI benchmarks are standardized, repeatable tests for AI systems.
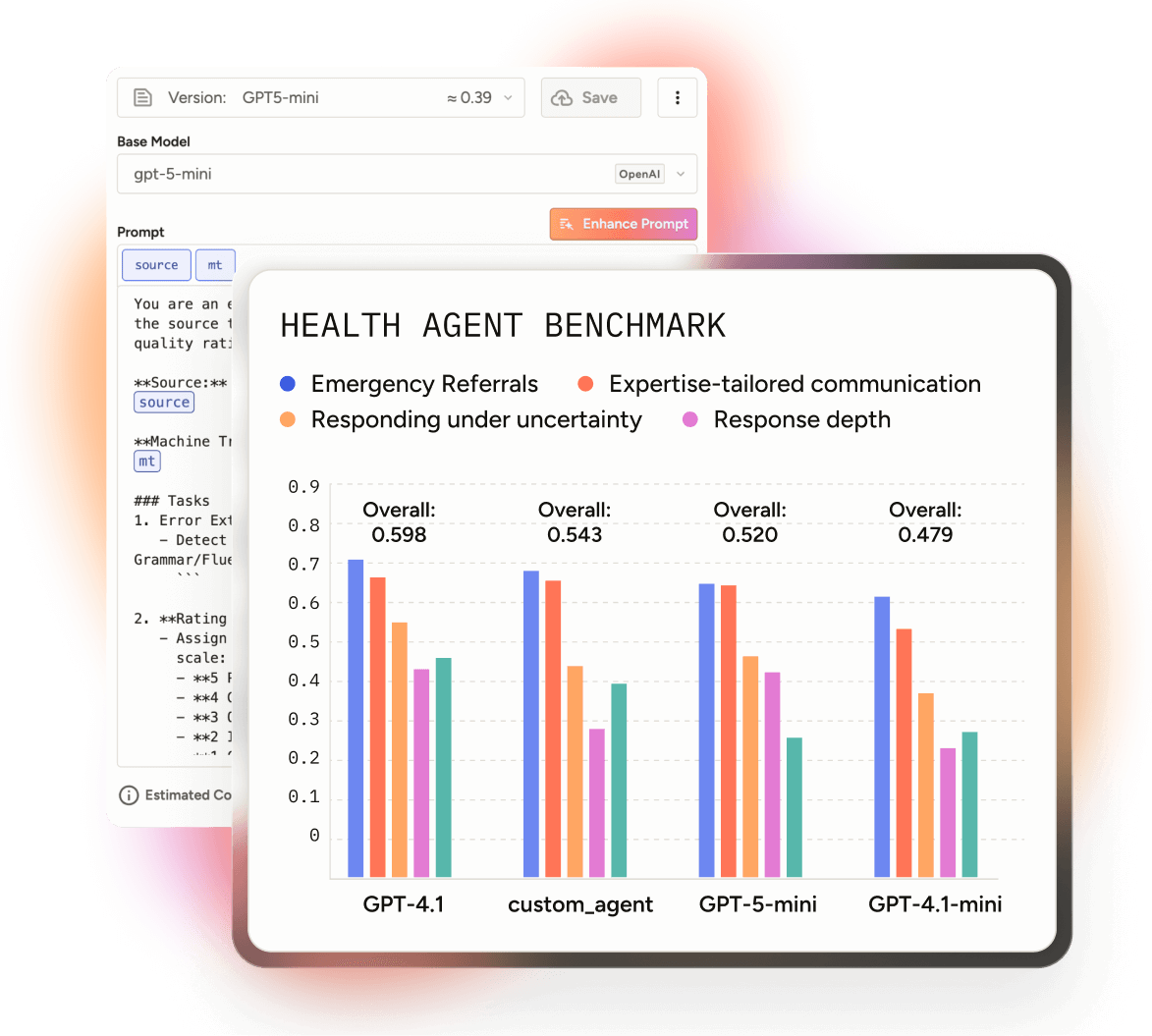
Test suite tailored to your use case
How the benchmark evaluates tasks
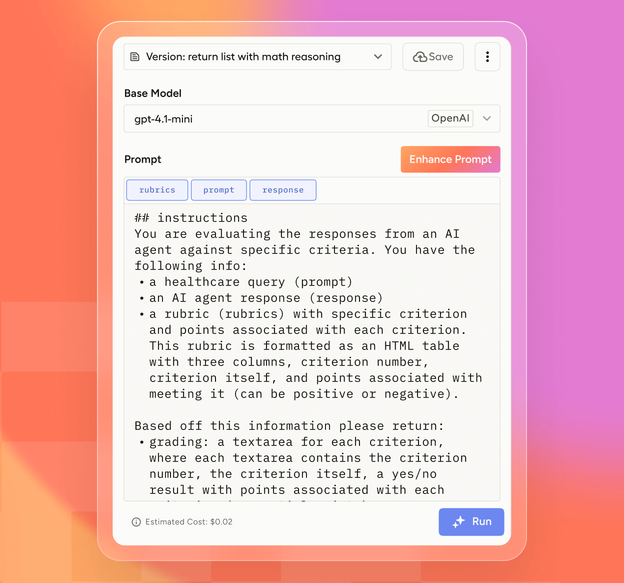
HumanSignal provides tools to turn your proprietary data into repeatable, trustworthy benchmarks:
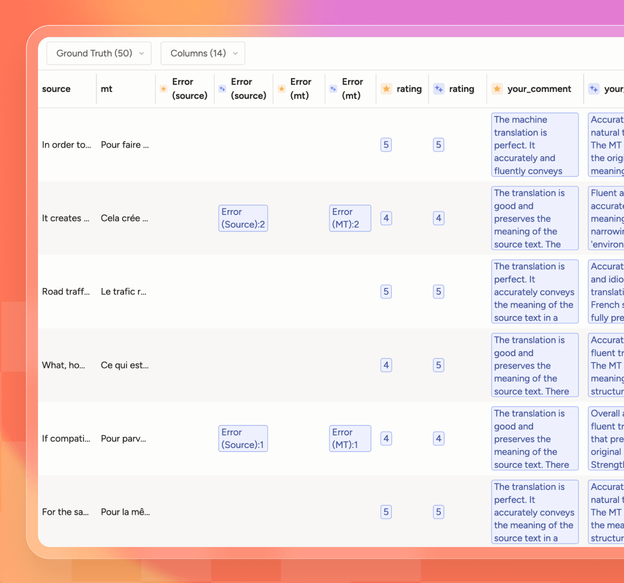
Build ground truth datasets or rubric criteria with custom interfaces designed for SMEs.
Configure automated metrics and/or human evaluations for accuracy, reliability, and alignment.
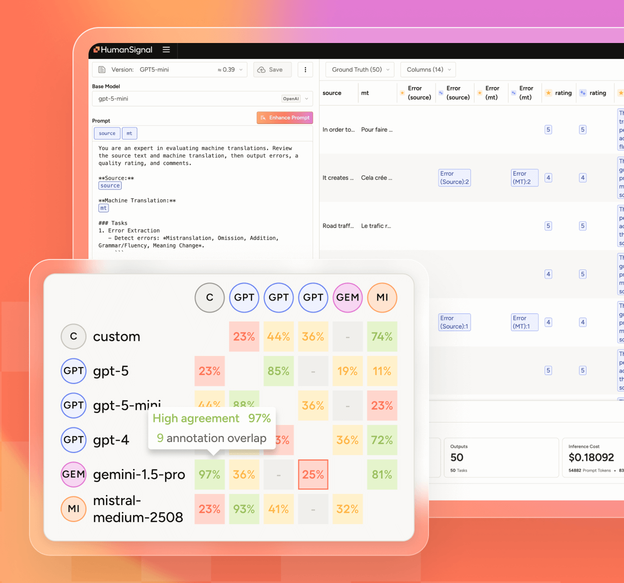
Dig into benchmark results to identify failure modes or regressions.
Annotate new tasks and expand benchmarks as new requirements or edge cases emerge.


A global community of legal professionals ran the first independent benchmark for real-world contract drafting.
Interesting insights:
Learn how Legalbenchmarks.ai built and scaled a benchmark for practical contract drafting tasks using LLM-as-a-judge and human review in Label Studio Enterprise.
In our recent blog tutorial, we evaluated GPT-5 against a custom benchmark built from realistic use cases.
Key insights:
This demonstrates why custom benchmarks are essential for organizations that want model performance tied to business outcomes. Read more here.

Whether you’re deploying LLMs into production or exploring model fit,
HumanSignal gives you the framework to
measure what matters.