Why Benchmarks Matter for Evaluating LLMs (and Why Most Miss the Mark)

Sheree Zhang
Sr. Product Manager
Sr. Product Manager
Every successful AI project masters one fundamental challenge: AI evaluation. As sophisticated AI systems are adopted across industries, the difference between impressive demos and reliable production systems comes down to proper evaluation.
Similar to how traditional software teams write unit tests to ensure components behave as expected, AI teams write AI evaluations (evals) to test whether models produce outputs appropriate for the scenario. As teams grow and projects scale, benchmarks play a crucial role in both worlds by providing a standardized structure to running these tests.
Welcome to our AI Benchmarks series - where we break down:
In this post, we’ll start with why evaluation is both critical and complex for LLMs. Then, we’ll introduce AI benchmarks and explore what makes them truly useful.
Teams building AI solutions naturally test “does this system solve the problem?” These evaluations reveal insights into system strengths, weaknesses, and opportunities for improvement. Importantly, benchmarks, a more standardized evaluation method, help provide consistent, repeatable assessments of system quality. However, for enterprise organizations, evaluation is not just a matter of quality.
The EU AI Act (in force as of August 2024) established the world’s first comprehensive legal AI regulation in an evolving regulatory landscape. This means systematic AI evaluation for performance, reliability, and safety is now a compliance requirement. Evaluation can no longer serve as an ad hoc exercise, but rather needs to be a strategic ongoing initiative.
Classical ML development followed a predictable routine. Split your labeled data, train your model, test on the holdout set, score with performance metrics (e.g. accuracy or F1), and iterate. This worked because classical ML systems focused on closed domain problems and produced outputs that could be objectively measured against correct (i.e. ground truth) labels.
LLMs, however, are non-deterministic by design. They’re:

Example use cases of classical ML and LLM applications
Instead of simple accuracy metrics, LLM evaluations rely on human assessment, model-based-judgements, or sophisticated rubrics to evaluate performance on a task. This shift from objective measurement to nuanced assessment calls for a new framework for evaluation: benchmarks.
Benchmarks standardize testing so you can repeatedly evaluate AI system performance on certain skills covered in the tasks. You may have seen some popular ones used to compare model performance in LLM leaderboards. Examples include:

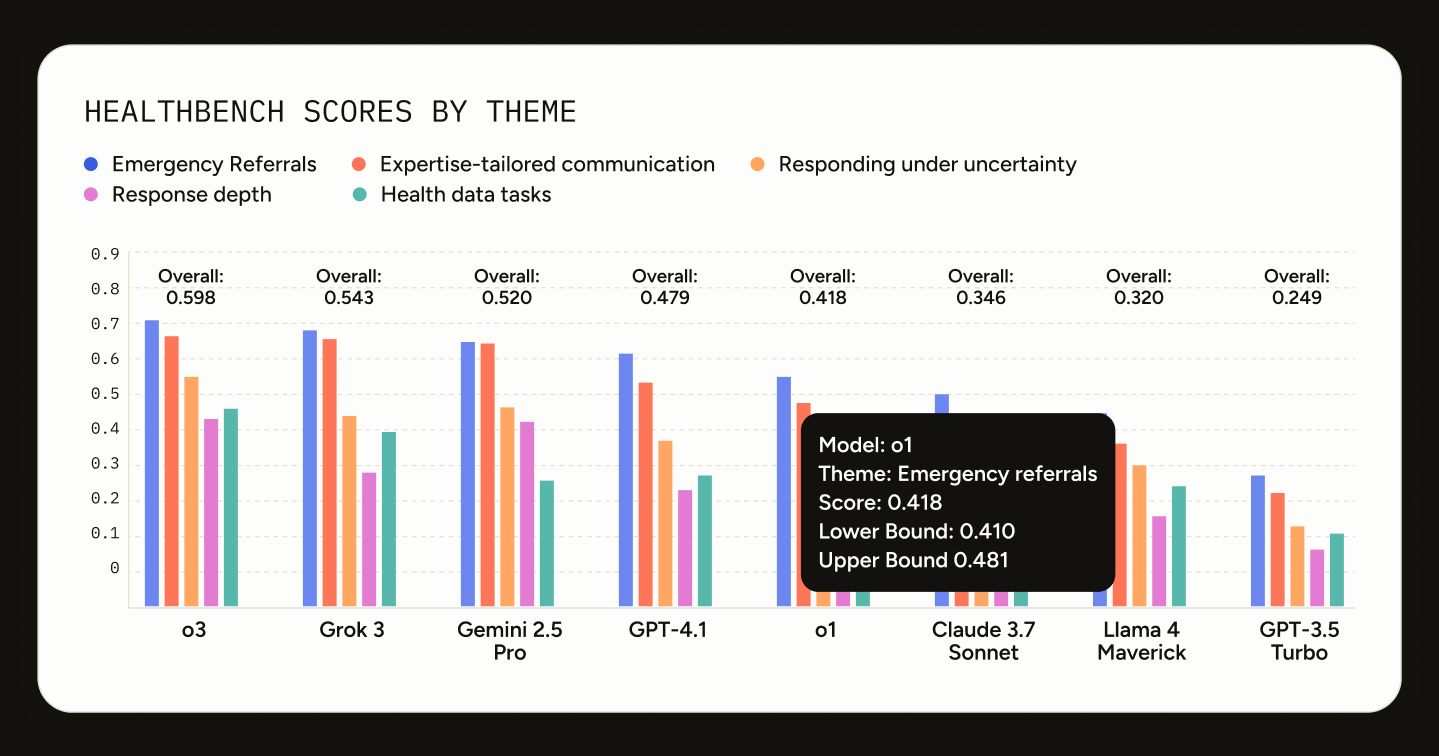
OpenAI HealthBench publication, May 12 2025
These examples comprise the two core components that make up an AI benchmark:
However, AI benchmarks have recently gotten a bad rep for serving more as a vanity metric than useful evaluation. And it’s true, off-the-shelf benchmarks generally miss the mark when it comes down to evaluating your own AI systems. Although they may be useful when initially selecting a foundation model to use, a question like “What is the prime factorization of 48” might not reflect the unique challenges your specific AI application faces.
Instead of relying on the test suites from public benchmarks, teams deploying consumer-facing AI systems collect or generate tasks that are tailored to their application’s users and use case. They include common, challenging, and even adversarial tasks, aiming to be representative of scenarios the system encounters in production. These tailored tasks serve as the foundation for custom benchmarks.
Note: We’ll dive deeper into the types of popular and custom benchmarks and when to use them in Part 2. A Guide to Types of AI Benchmarks. Stay tuned!
To recap, an AI benchmark contains a set of tasks and a scoring method. An effective benchmark is also highly relevant, interpretable, and practical for your use case. Generally, this means creating a custom benchmarks with the following characteristics:
As AI systems become core infrastructure, test-driven development will become the norm. In the same way software teams write test suites to protect their codebase, AI teams will maintain custom benchmarks to protect the quality of their systems. These benchmarks will encode the goals we want our applications to achieve and define the meaning of quality in our context.
This is the first post in our AI Benchmarks series - your guide to building effective, scalable AI evaluations. Whether you’re experimenting on your own AI system or you’re a seasoned practitioner looking to strategize an enterprise evaluation workflow, this series has something for you. In the next post, we’ll break down the different types of AI benchmarks and how to use them effectively.

A practical maturity model for taking benchmarks from proof-of-concept to versioned, continuously evolving evaluation that keeps up with models, prompts, and agent workflows.


What happens when you let AI judge AI? A pioneer benchmark for quality estimation in machine translation.

GPT-5 is out now -- but how good is it, really? In this post, we'll show you how we created our own custom Benchmark to evaluate GPT-5.