
For Frontier AI Labs
Evaluation. Alignment. Agentic tasks. Domain expertise. Data services for the teams building frontier models.
Your post-training researchers are designing data generation pipelines, not managing vendors. We operate the human side of that pipeline so they don't have to.
Services
Human feedback, preference data, and reward signals calibrated to your model's capability level.
Evaluation is its own discipline now. We build the datasets your eval teams run against.
For labs shipping open-weight models or selling to sovereign customers, safety data is a compliance requirement, not a nice-to-have.
General-purpose raters can't evaluate experimental designs or validate scientific reasoning. We maintain vetted expert pools.
Your models learn from video, images, audio, and 3D space. The training data needs human quality signals across every modality.
The quality layer between your data pipeline and your training run.
Featured capabilities
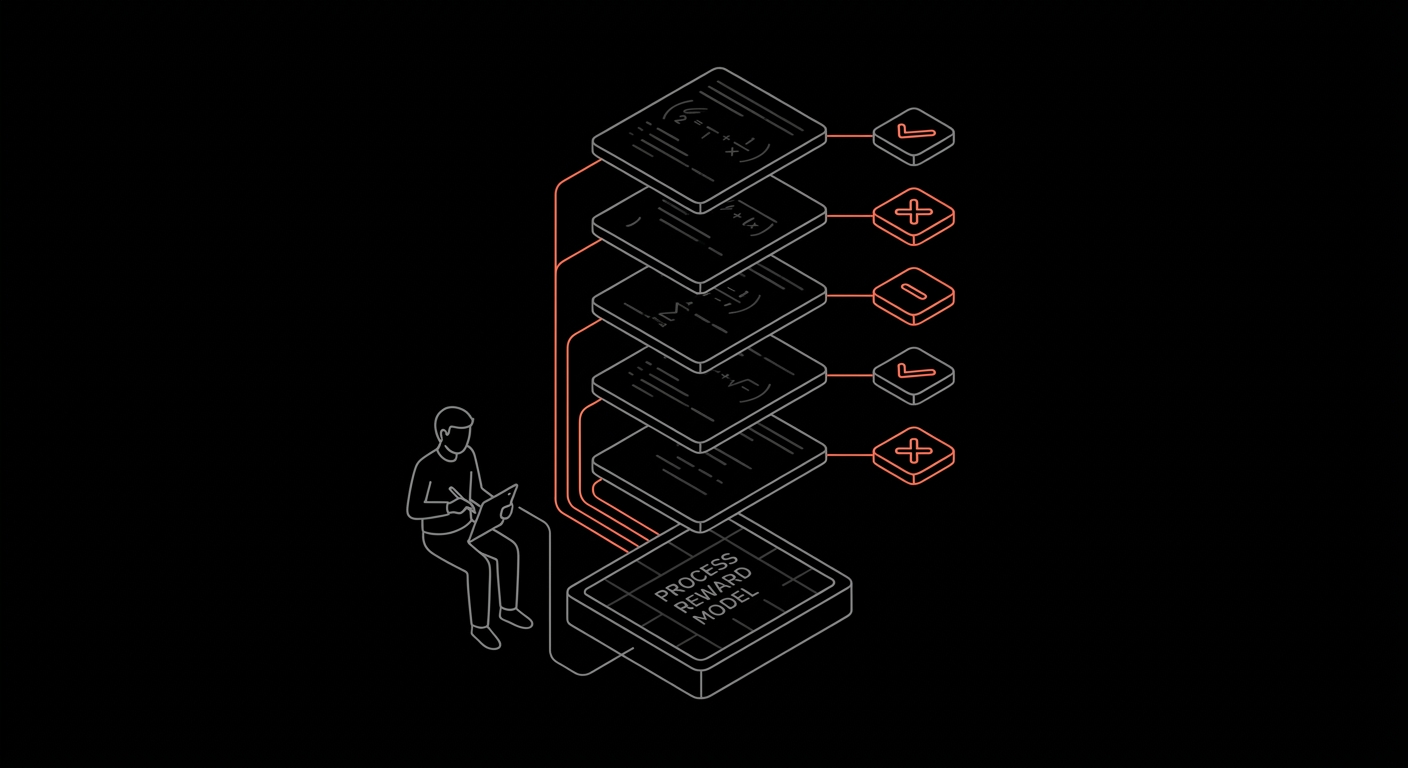
Step-labeled reasoning traces and rejection-sampled rollouts that feed process reward models, not just outcome scores.
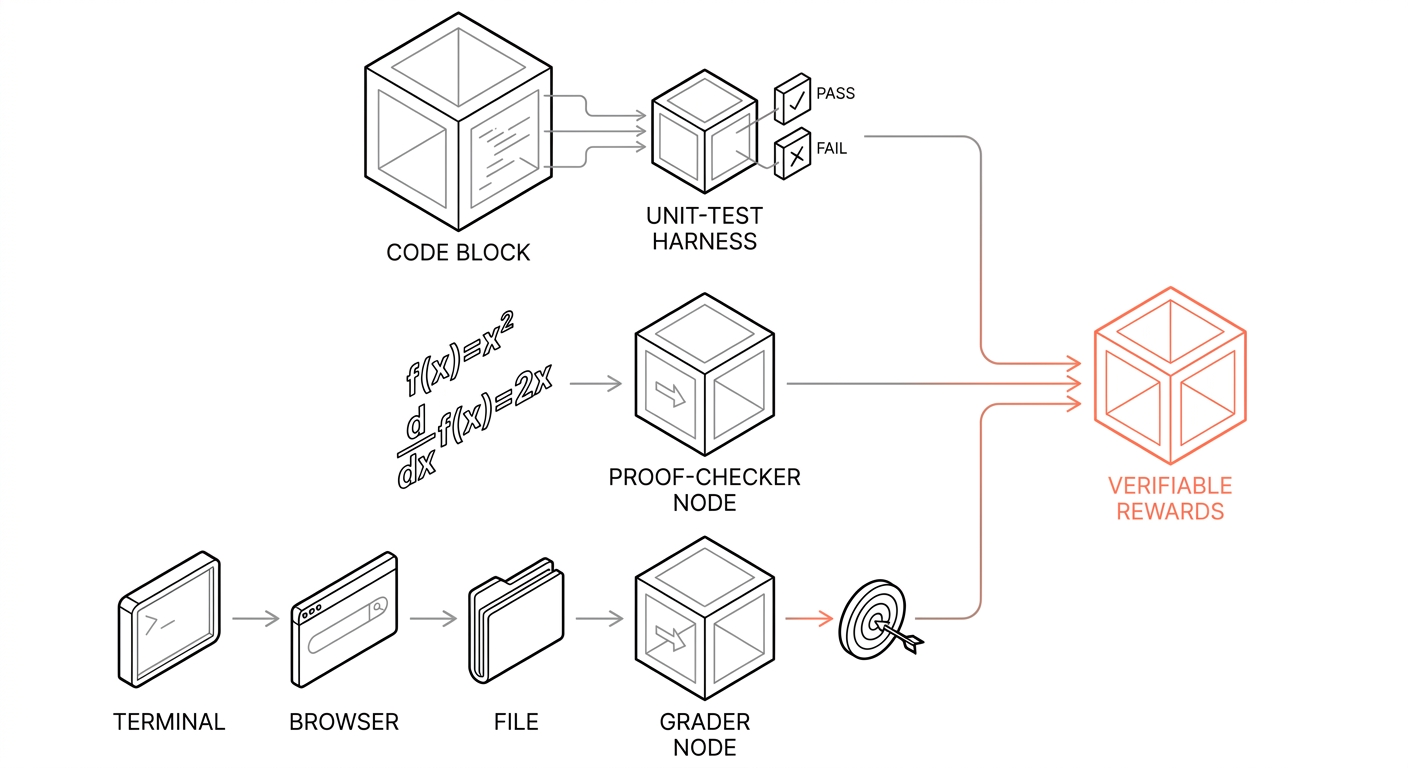
Code tests, proof checkers, and grader nodes convert rollouts into verifiable reward signal for RL training.
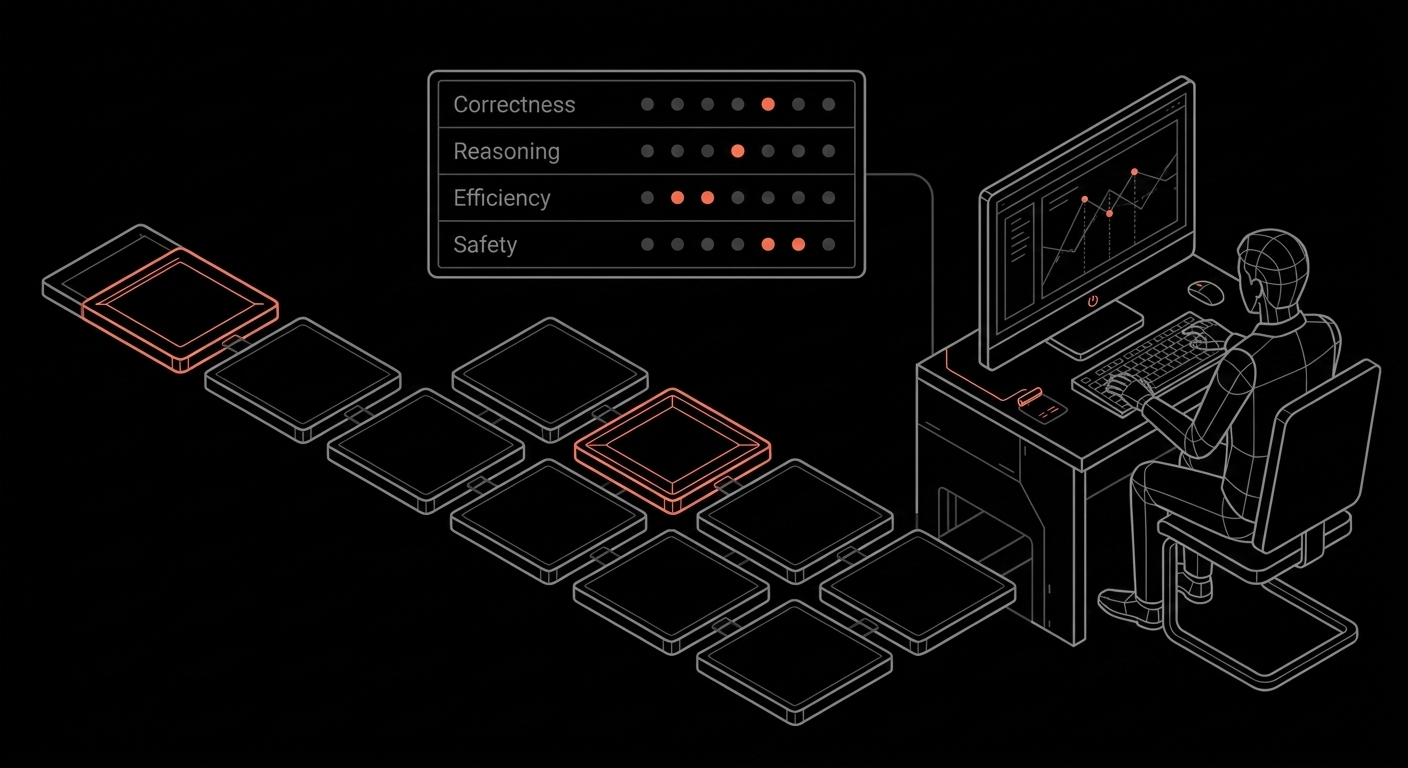
Calibrated domain experts grading trajectories on the dimensions that matter: correctness, reasoning, efficiency, safety.
How we work
Your team already knows the platform. No new tooling to learn, no vendor lock-in, full export flexibility into your training pipeline.
Calibrated rater pools matched to your model's capability level. Real-time inter-annotator agreement tracking. Multi-tier review workflows. Data doesn't ship until quality thresholds are met.
SOC 2 Type II. Air-gapped deployment in your infrastructure. NDA-covered workforce. Your training data is your moat, and we treat it that way.