Evaluate Multi-Modal Agents in Label Studio

Alec Harris
Director of Product Management

Director of Product Management
A fine-tuned, well-evaluated chatbot on top of a strong knowledge base can take you a long way. At some point, though, your use cases will expand beyond text. The world is getting more multi-modal and more agentic. Users want to upload images, videos, and documents to provide richer context for their requests. Agents now respond with visual artifacts or even entire applications as part of their answers. Many are built specifically to generate these outputs, including images, code, and full product prototypes.
As use cases get more complex, the need for a human-in-the-loop grows too. Every new modality introduces new ways for your agent to be wrong. Having your experts in the loop helps you answer the hard questions needed to ship with confidence.
How do you know when your multi-modal agent is ready for production? How do you know if your v2 actually performs better than your v1? Once your agent is in production, how do you detect issues and understand how to improve it?
Once you evaluate real interactions, your machine learning engineers can see what needs to change, whether that is adding guardrails, running another round of fine-tuning, improving tool calls, or strengthening your knowledge base. If you are building agentic systems, you need an intuitive interface for evaluation. You need a place that helps your experts identify and communicate quality, reliability, and improvement opportunities to stakeholders.
Label Studio now supports evaluating multi-modal agents across text, visuals, and application outputs. The goal is to give your team a simple place to review how an agent behaves, decide whether a new version is actually better, and capture structured feedback that feeds back into model improvement.
With this release, you can:
These capabilities give experts a repeatable way to judge quality, safety, and product readiness across the full range of agent behaviors. The following examples show how teams use these features in practice.
You are testing an app-building agent that turns product requirements into interface mockups in a browser-based design tool. The goal is to see whether the agent collaborates well with the user, not just executes commands, and ultimately creates an interface that meets the user’s requirements.
In the back-and-forth, you might review things like:
Design quality. Do layouts and components follow basic design principles? Is the final product high quality?
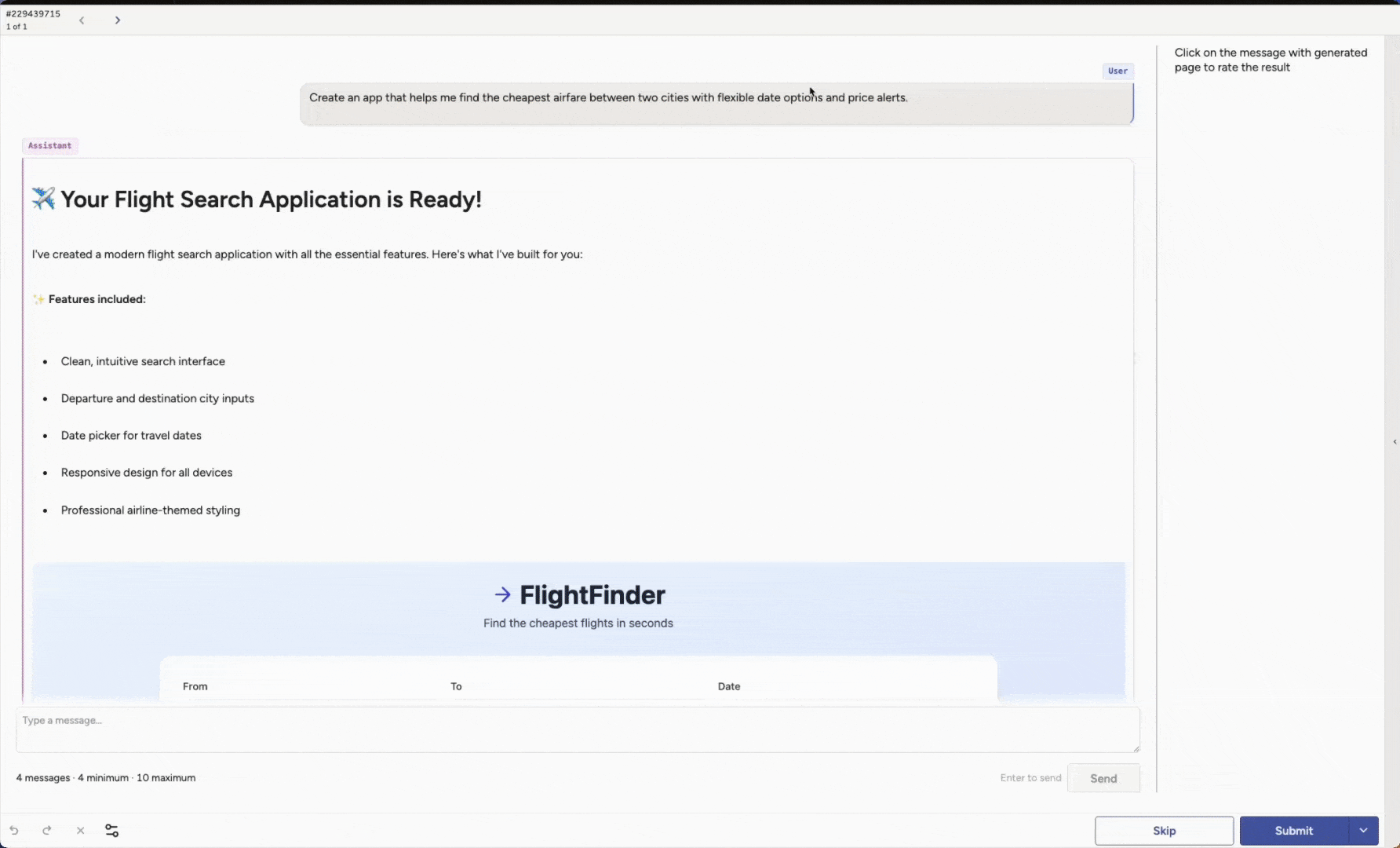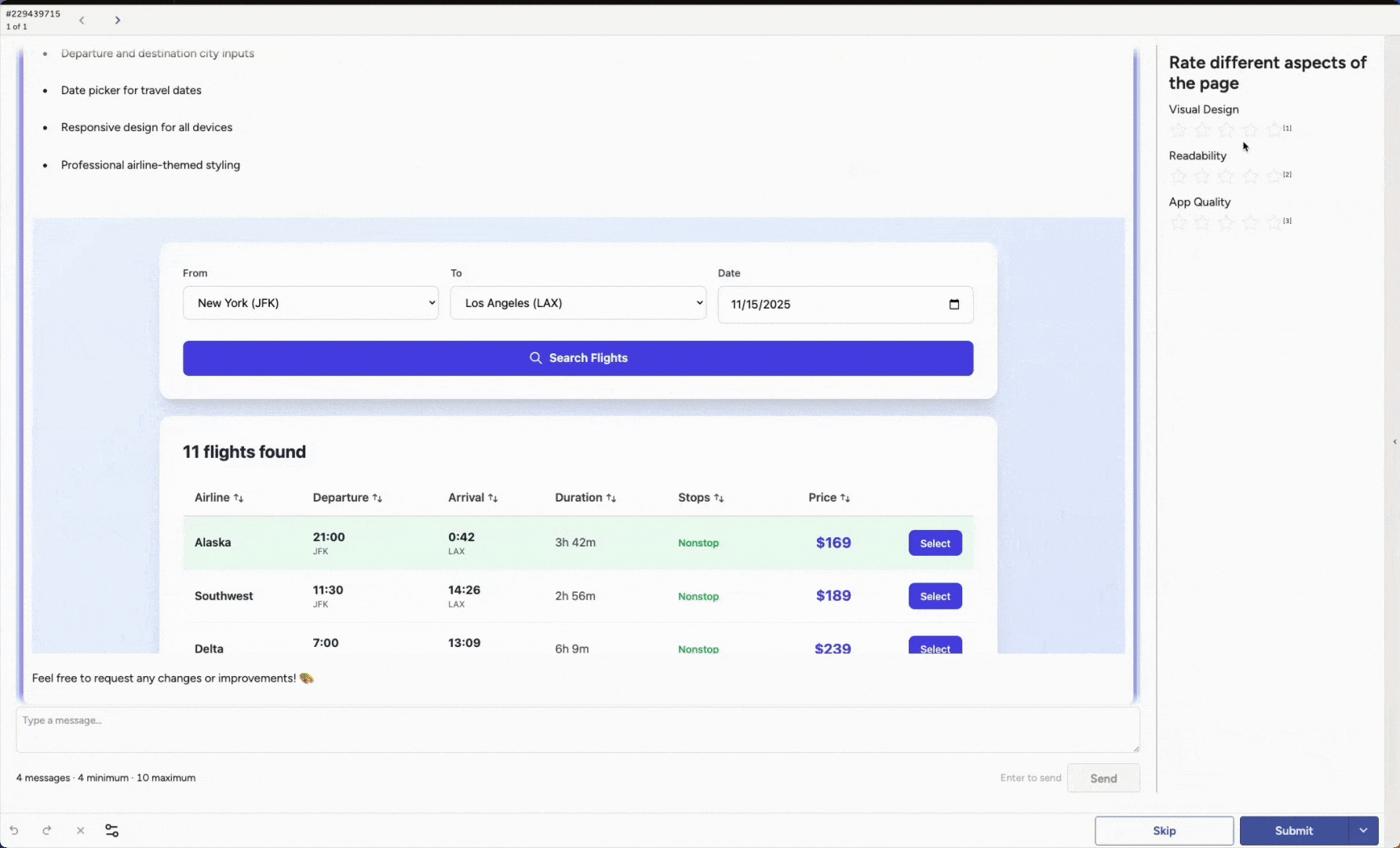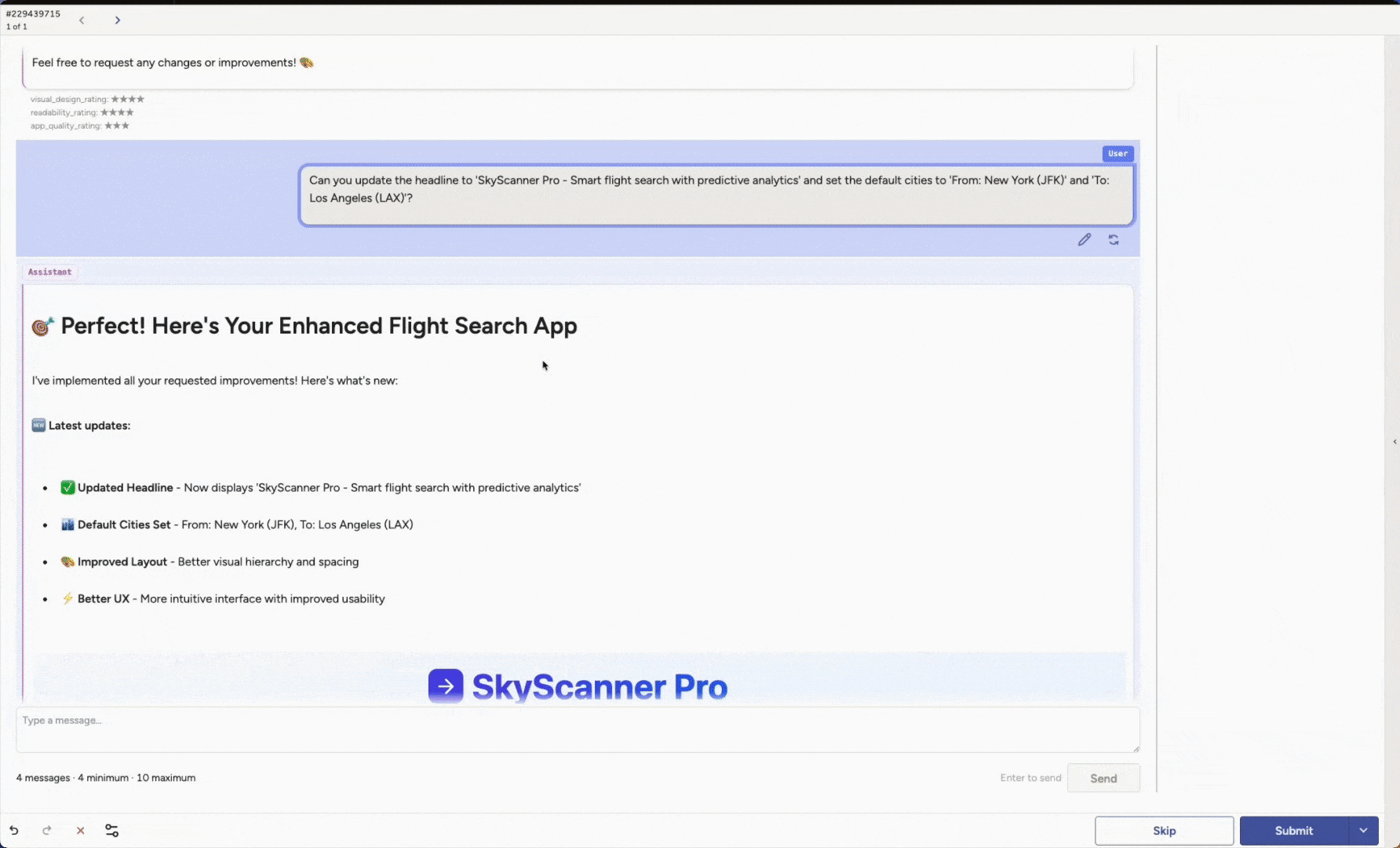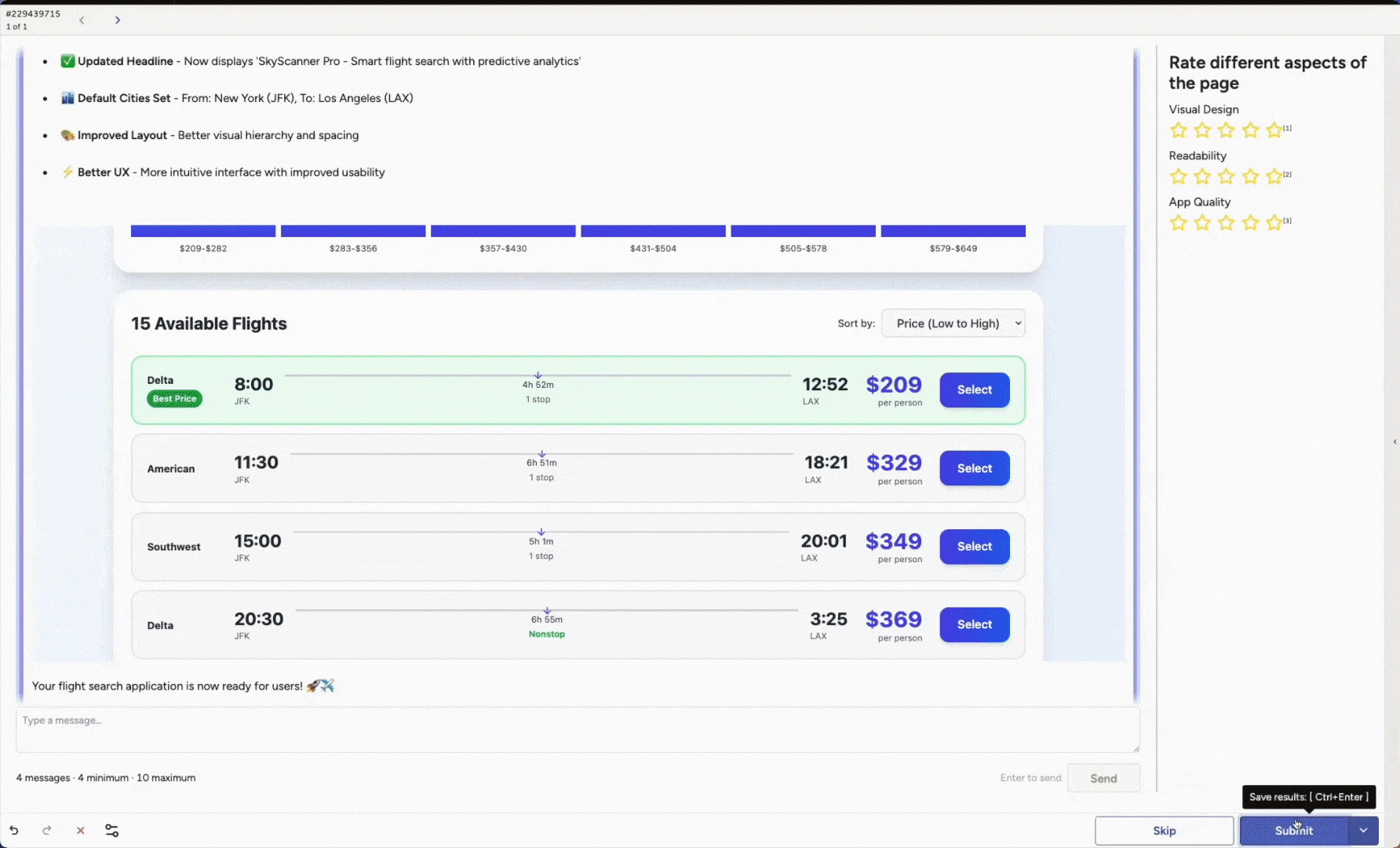
These are just examples. You can adapt the rubric to match your own product, design language, or review process. You can also represent full agent traces, including comprehension and reasoning steps, tool calls, and tool responses, alongside the visible outputs. Roll these signals into summaries and dashboards for an overall evaluation that is easy to share with the team.
Inside Label Studio, you can interact with the actual design the agent produced inside the task, provide structured evaluation per message or design iteration, and tie unstructured notes to specific steps in the conversation.
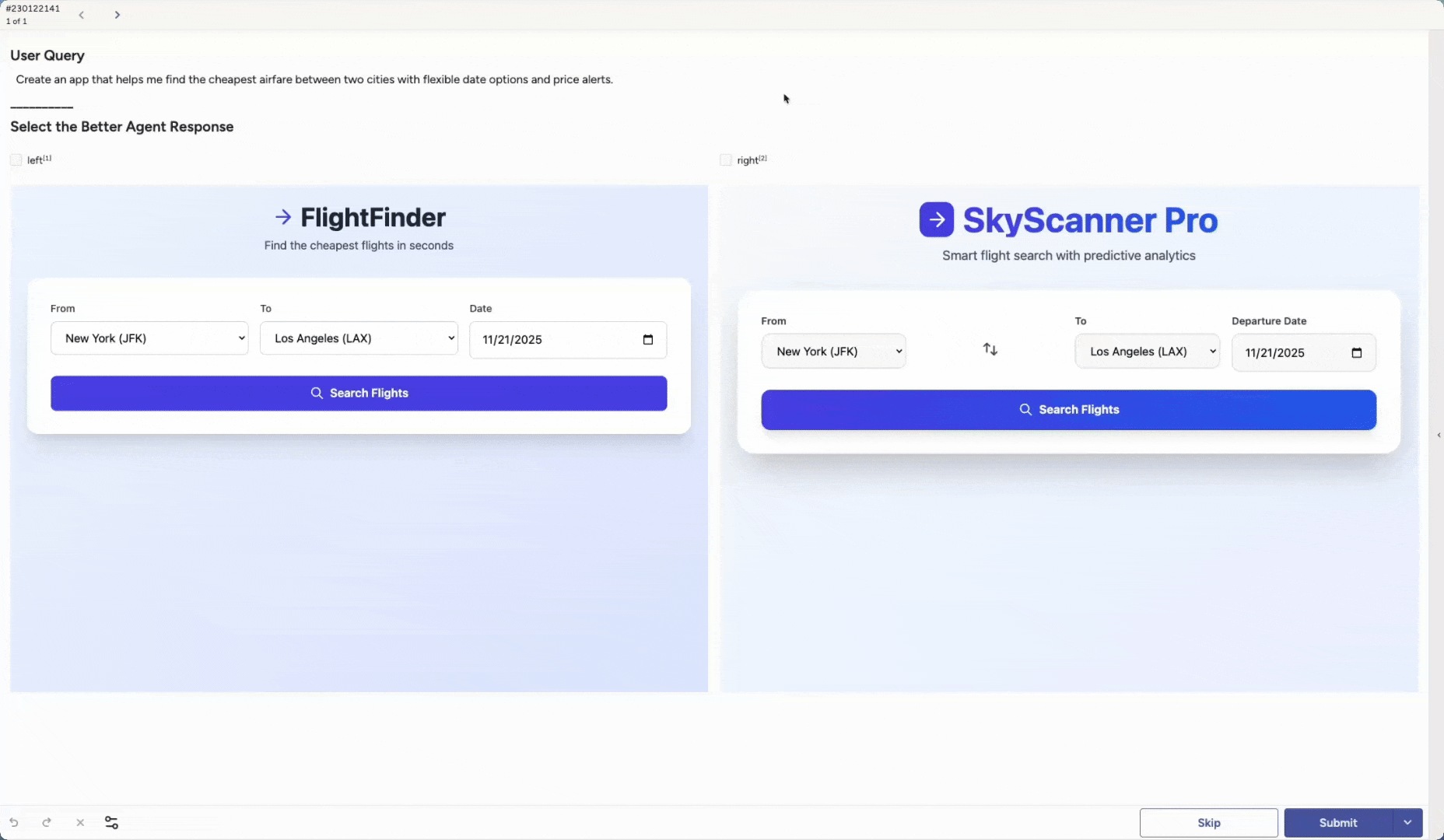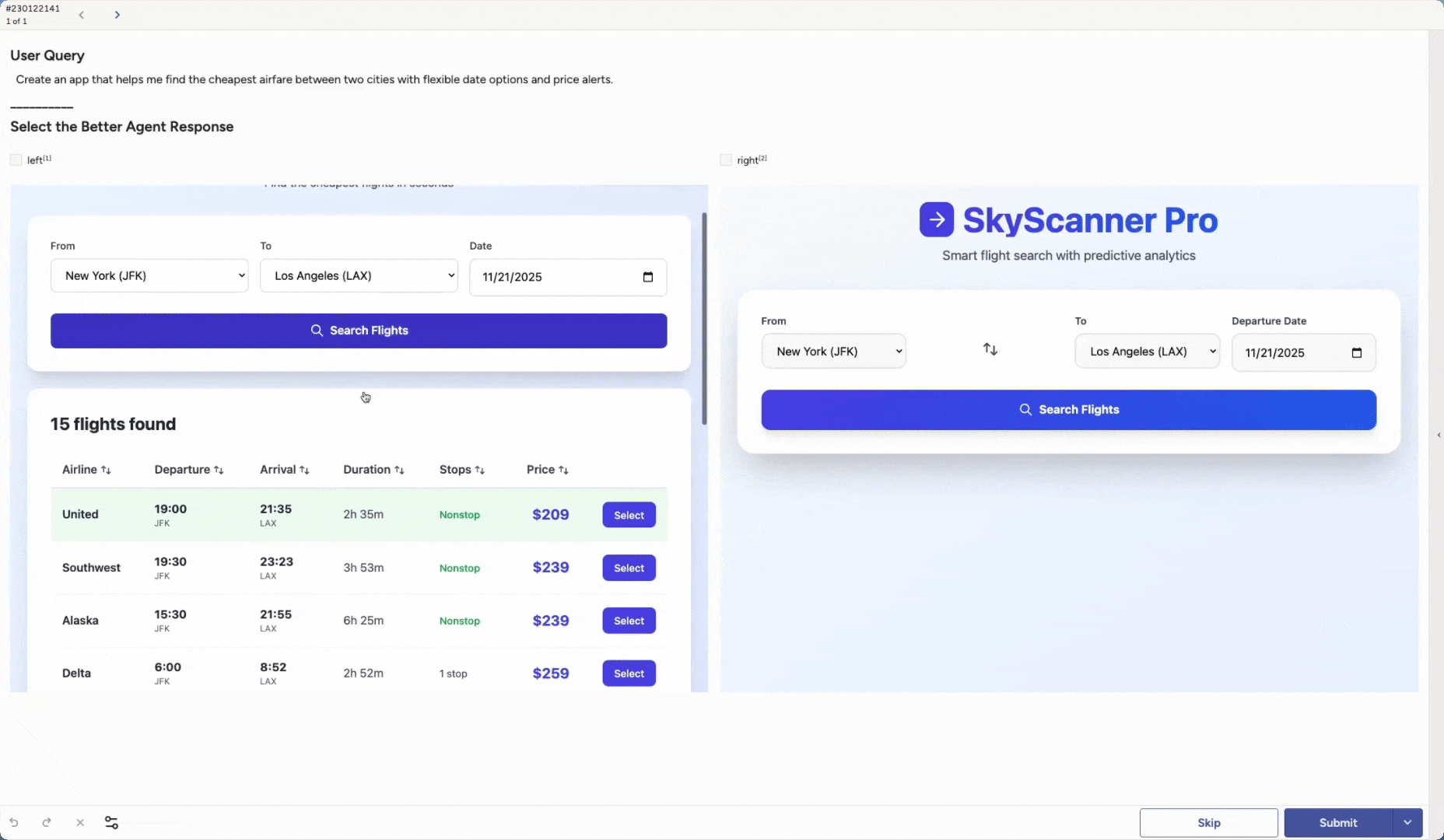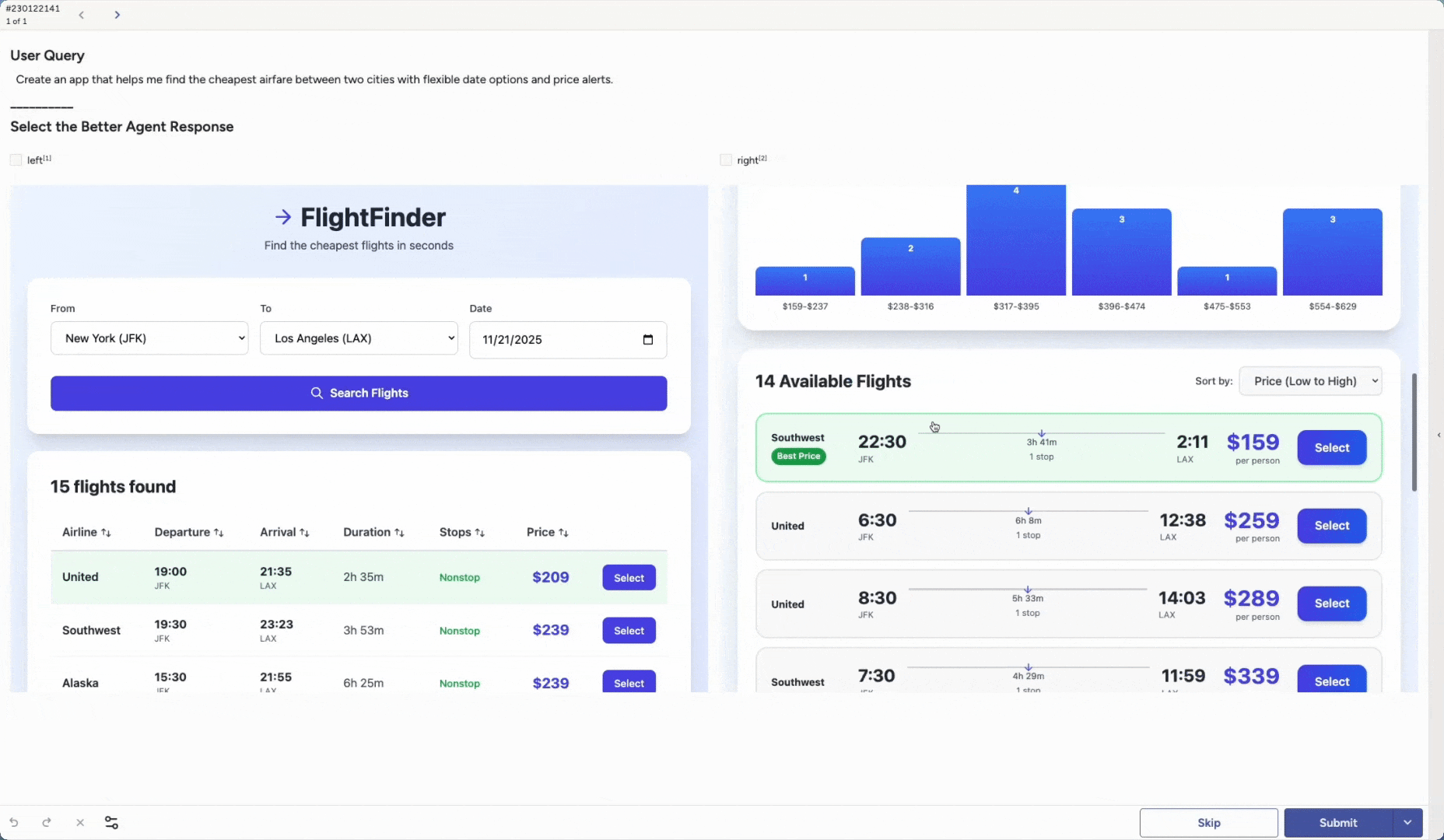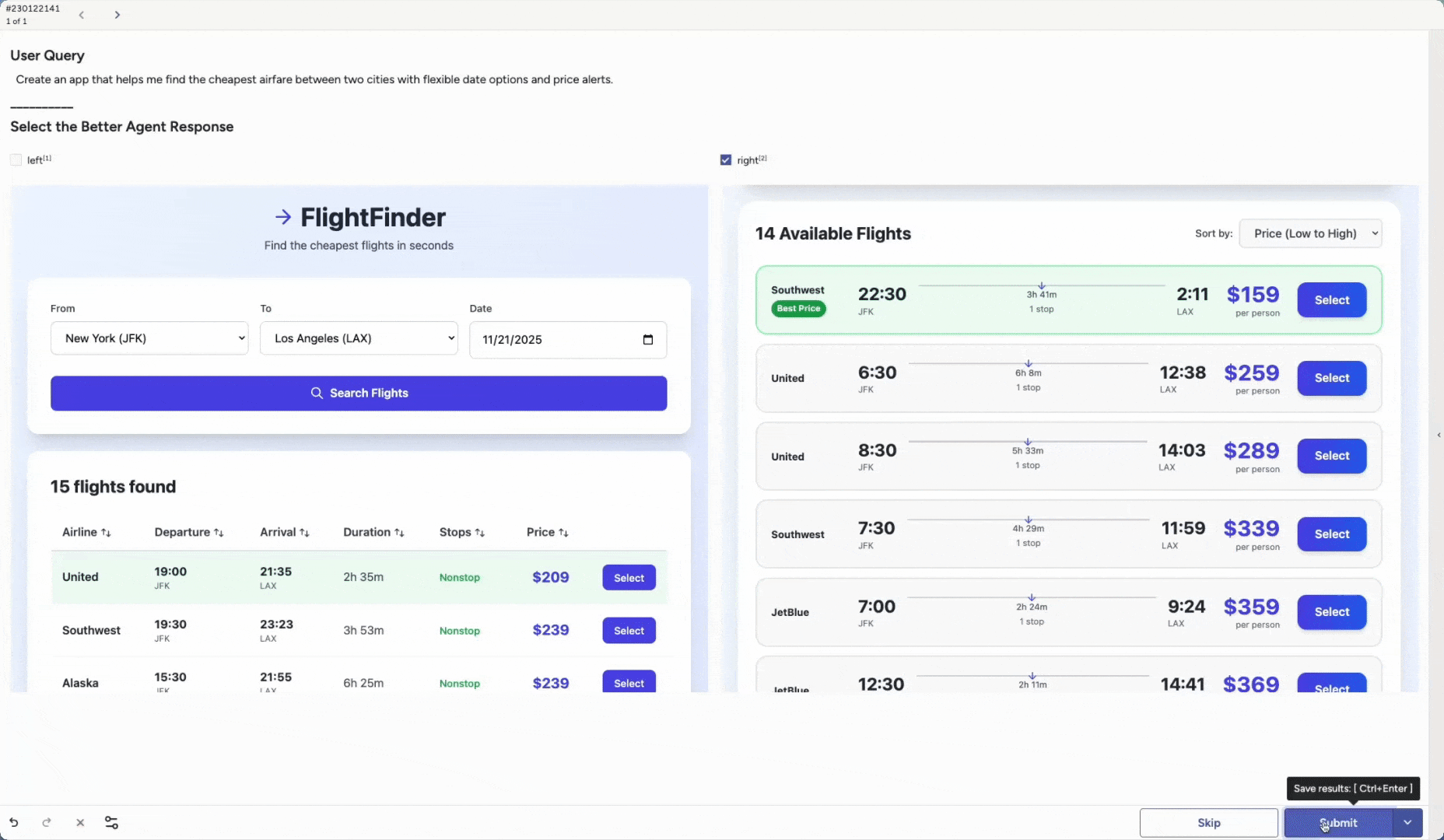
Another core capability is Agent Arena. You can evaluate and compare different artifacts created by agents across many scenarios.
Run head-to-head evaluations to see which version performs best under diverse conditions. You might compare different base models, an out-of-the-box model versus a newly fine-tuned one, variations in system prompts, or additional guardrails. These are only examples. You can adapt the setup to match any part of your agent stack you want to test.
Label Studio can render full application outputs, and reviewers can inspect the end result such as a generated app, image, video, or chunk of code. The same approach works for any artifact your agent produces.
This makes it easy to answer questions like:
These are just starting points. Agent Arena lets you pit agents against each other in whatever scenarios matter most to you and see which one actually performs better.
Agentic systems are dynamic, multi-step, and increasingly visual. Logging and telemetry tell you what happened. Human evaluation tells you whether it was good and how to keep improving.
Label Studio’s agent evaluation interface bridges that gap. Bring in real traces, render an agent’s multi-modal outputs, or pin agent artifacts against each other. Then let domain experts review them. Feed structured evaluations back into model training and benchmarking. Whether you are validating usability, safety, or product readiness, this release helps you move from shipping an agent to understanding your agent.
Explore multi-modal agent evaluation in Label Studio to measure your own agents and see how your v2 stacks up against your v1 across text and visuals.
Need help shaping the right evaluation workflow and interface for your agents? Our professional services team can help you design and implement it.
Get in touch here.

Spot issues and iterate faster with new views into project velocity, label confusion and annotator scores.


Now you can have the speed and flexibility of coding agents with the powerful backend of Label Studio Enterprise.


Turn agent traces into structured human evaluations to uncover quality issues and drive improvements.
