Guide: Building a Data Labeling Practice for Machine Learning and Data Science

Label Studio Team

As the industry shifts from model-centric to data-centric AI, building an efficient and highly performant data labeling practice is becoming increasingly strategic. We recently published a new guide to data labeling for machine learning and data science, designed for data science and MLops leaders who are taking steps to building and managing data labeling functions. Download the free guide to learn about the four core pillars of data labeling—data, process, people and technology.
While data is critical for building AI models, raw data doesn’t have enough context to train or fine tune a machine learning model. Data labeling is the process of tagging or labeling raw data so a machine learning model can learn from the meaningful context. The ML model then uses the human-provided labels to learn the patterns, resulting in a trained model that can make predictions on new data.
At the most basic level, a label can indicate whether a video has an airplane in it or if an audio clip has certain words uttered. These labels or tags represent a class of objects and help the machine learning model identify the object(s) when they come across data without a label or tag. This example also represents “common knowledge” data labeling, which means most people (and now models) can tag or classify these attributes based on widely understood criteria.
Companies who are leveraging machine learning and AI for strategic business initiatives, however, need to apply more specialized business context and domain expertise in order to benefit from truly differentiated and competitive predictions. As we automate or outsource the labeling of common knowledge datasets, the goal is to make use of human annotators with context and subject matter expertise for more strategic and high value tasks, as well as human supervision of programmatically and externally labeled datasets.
Building a data labeling function to support this human workflow in the most efficient and effective way is highly strategic to companies investing in machine learning and AI. In this data labeling overview, you will learn:
For a machine learning project to be successful, organizations need to have a well-designed, efficient, and scalable process that they can actively monitor to ensure high-quality and accurate results. Data labeling sits at the core of the ML process. Think of it as an assembly line that takes source data as raw inputs and creates meaningful metadata in a format that machine learning algorithms can understand and use to make predictions as outputs.
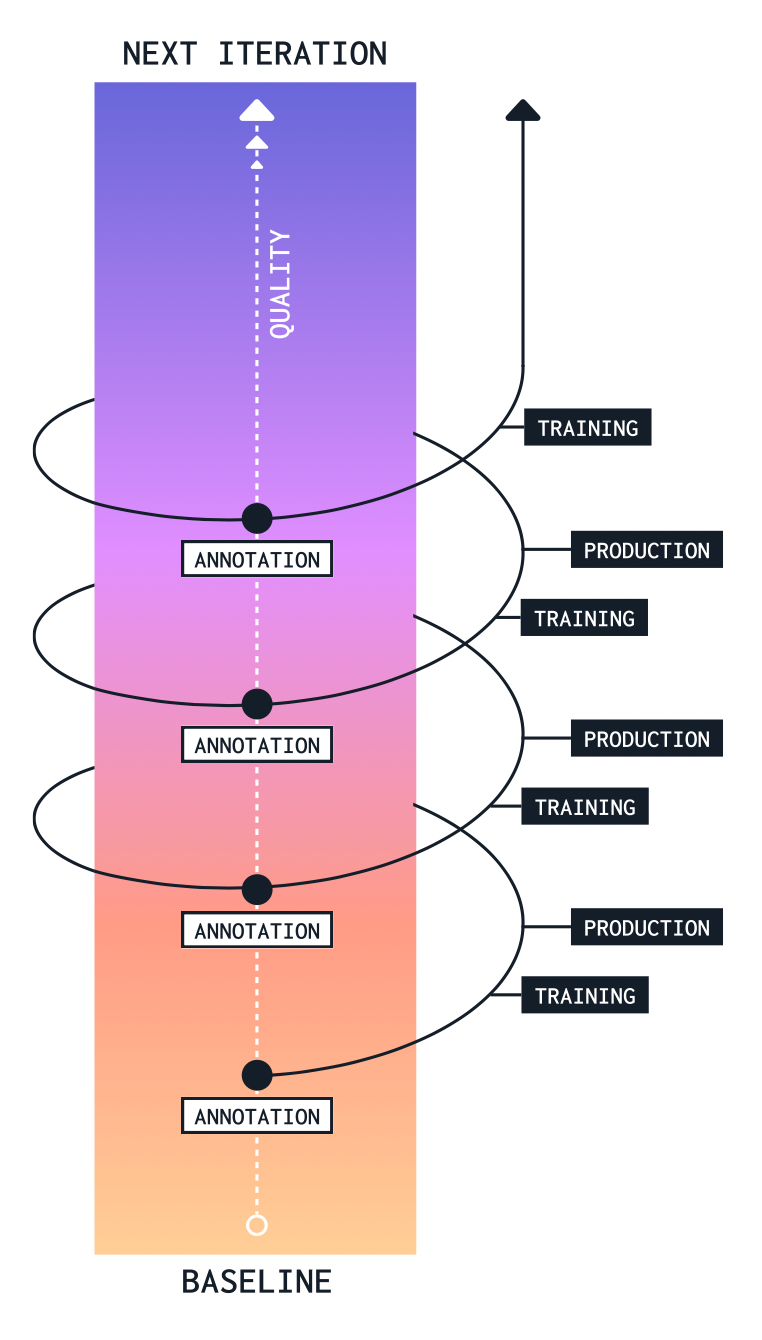
Data labeling is an iterative process. The data labeling process isn’t complete after you ship the first ML version. There is a lot of trial and error involved. Based on feedback from the model, you are constantly optimizing the models and redefining your goals for the next deployment iteration. Therefore, there has to be a process for constant feedback, monitoring, optimization, and testing.
While every data labeling project is unique, typically, projects will align to one of three common stages.
The data labeling process for training your initial ML model encompasses generating the unlabeled dataset and breaking it into labeling tasks assigned to annotators who follow instructions to label each sample properly. After assessing quality and fixing discrepancies, the process completes with your labeled data set, which is fed to your ML models.

Once a model is in production, you may need to label additional data to correct a model whose accuracy has degraded or because there are now new data that, once labeled, will enhance the model’s predictive accuracy.
For example, a sentiment classifier for an eCommerce site pre-trained on data from eBay might not perform very well with your user data. This scenario is one of the examples of data drift—situations when the original dataset differs from the actual data being sent to the model. Data drift is a signal to continue the labeling process to get the model back on track.
Here, the data labeling process involves running the pre-trained model over the initial dataset and logging the predictions. After this, we explore how the pre-trained model performs with our dataset. For example, is there a specific bias common to the algorithm, and in what areas is it failing? Taking into account this analysis, we can start relabeling our new dataset. We recommend you follow the workflow below:
Once this is done, prepare your dataset for training, test the model again, and keep iterating the process until you get more accurate results.
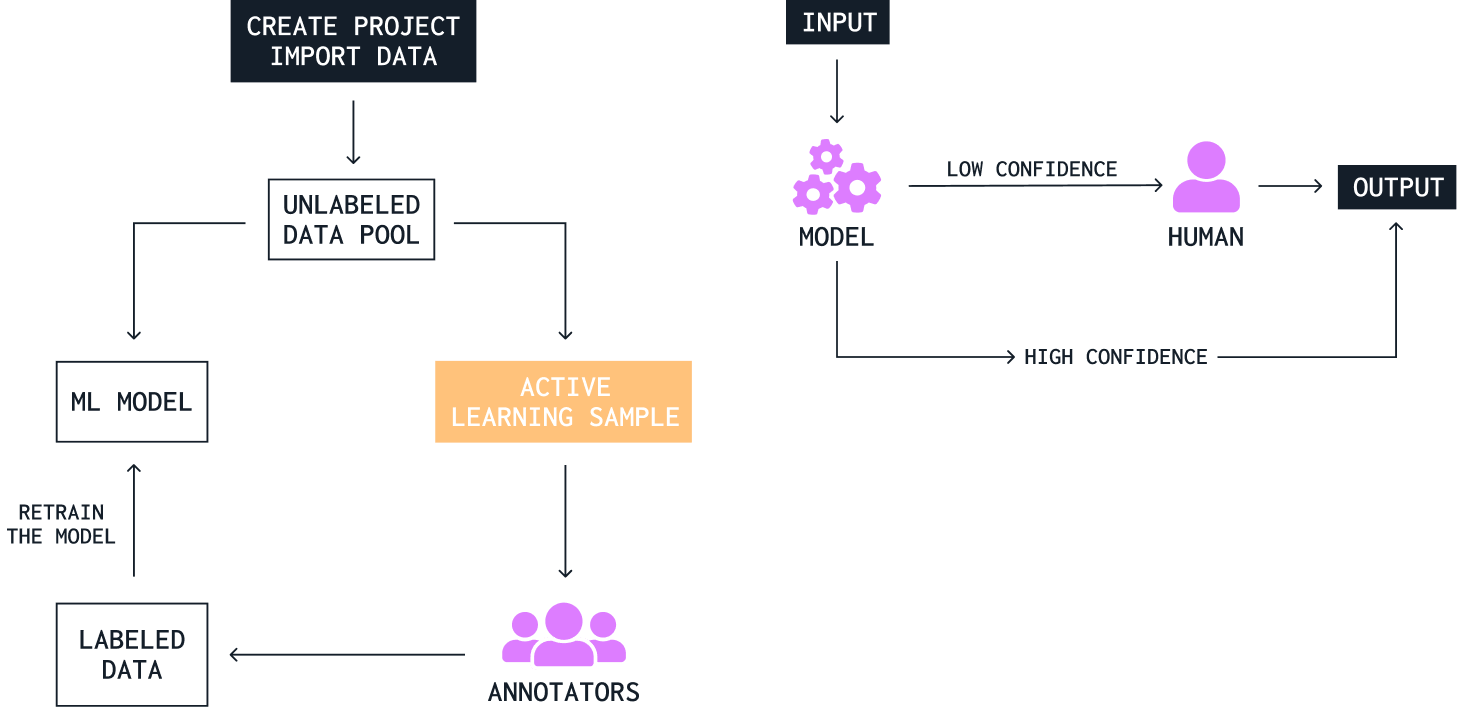
Because of the tremendous quantity of data needed to train ML models, manual data labeling can be time consuming. One way to speed up the data labeling process is to combine manual data labeling with artificial intelligence to enrich and label a dataset faster, a technique known as “Human in the loop” (HITL).
The HITL process begins by having humans label a dataset sample for training a seed model. The seed model is then used to train machines to identify and label data points in a transfer-learning model. This transfer-learning model automatically labels the rest of the dataset used in the ML model.
Once the model is in production, it often uses a prediction (certainty) score to automatically send high- confidence predictions to users and low-confidence predictions to humans to review, for example, if a machine is unconfident about a certain decision, like if a particular image is a cat. Humans can score those decisions, effectively telling the model, “yes, this is a cat” or “nope, it’s a dog.” This approach of humans handling low-confidence predictions and feeding them back to the model to learn from is referred to as active learning.
In active learning, the model gives answers when it’s sure and confident about what it knows, but it’s free to ask questions to the human whenever it is in doubt or wants to learn more. HITL encompasses active learning approaches as well as the creation of datasets through human labeling. This mechanism is a constant process that occurs all through the ML life cycle, from initial training to model fine-tuning. It allows humans and machines to interact continuously, making development faster and more cost efficient.
The key to a well-oiled data labeling process is tracking each process time, taking constant feedback from team members, and constantly looking for improvement opportunities. Here are some best practices to improve your data labeling process.
Download the free guide to access the rest of the content, or contact our expert sales team to learn how Label Studio Enterprise can enable your data labeling practice.

Learn how to evaluate AI agents in production by moving from single-turn metrics to trajectory evaluation using human-in-the-loop trace review.


Static tests fail multi-step AI agents. Learn why the eval lie causes silent failures and how a trajectory-based evaluation framework fixes it.

Observability shows what happened; domain experts explain why, and their structured reviews turn raw traces into targeted fixes that finally close the last mile.
